Using named matches from Go regex
Categories:
Mastering Go Regex: Extracting Data with Named Capture Groups
Learn how to effectively use named capture groups in Go's regexp package to extract specific data from strings, making your parsing robust and readable.
Regular expressions are a powerful tool for pattern matching and data extraction. Go's standard library provides the regexp package, which offers robust functionality for working with regular expressions. One particularly useful feature is named capture groups, allowing you to refer to matched substrings by a descriptive name rather than a numerical index. This article will guide you through the process of defining and using named capture groups in Go, enhancing the readability and maintainability of your code.
Understanding Named Capture Groups
In regular expressions, a capture group is a part of the pattern enclosed in parentheses (). It 'captures' the substring that matches that part of the pattern. A named capture group takes this a step further by allowing you to assign a name to the group. In Go's regexp package, named capture groups are defined using the syntax (?P<name>pattern). The name is an identifier you choose, and pattern is the regular expression for the data you want to capture.
flowchart TD
A[Define Regex Pattern] --> B{"Contains `(?P<name>pattern)`?"}
B -- Yes --> C[Compile Regex with `regexp.Compile`]
C --> D[Find Matches using `FindStringSubmatch`]
D --> E[Retrieve Group Names with `SubexpNames`]
E --> F[Map Matches to Names for Easy Access]
B -- No --> G[Use Indexed Capture Groups]
G --> FWorkflow for using named capture groups in Go regex
Defining and Using Named Groups in Go
Let's walk through an example to see how to define and use named capture groups. We'll parse a log line that contains a timestamp, log level, and message. Without named groups, you'd rely on numerical indices, which can be fragile if the pattern changes. Named groups provide a more resilient and self-documenting approach.
package main
import (
"fmt"
"regexp"
)
func main() {
// Define a regex pattern with named capture groups
// (?P<timestamp>...) captures the timestamp
// (?P<level>...) captures the log level
// (?P<message>...) captures the log message
logPattern := regexp.MustCompile(`^(?P<timestamp>\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}) \[(?P<level>[A-Z]+)\] (?P<message>.*)$`)
logLine := "2023-10-27 14:35:01 [INFO] User logged in successfully."
// Find all submatches, including the full match and captured groups
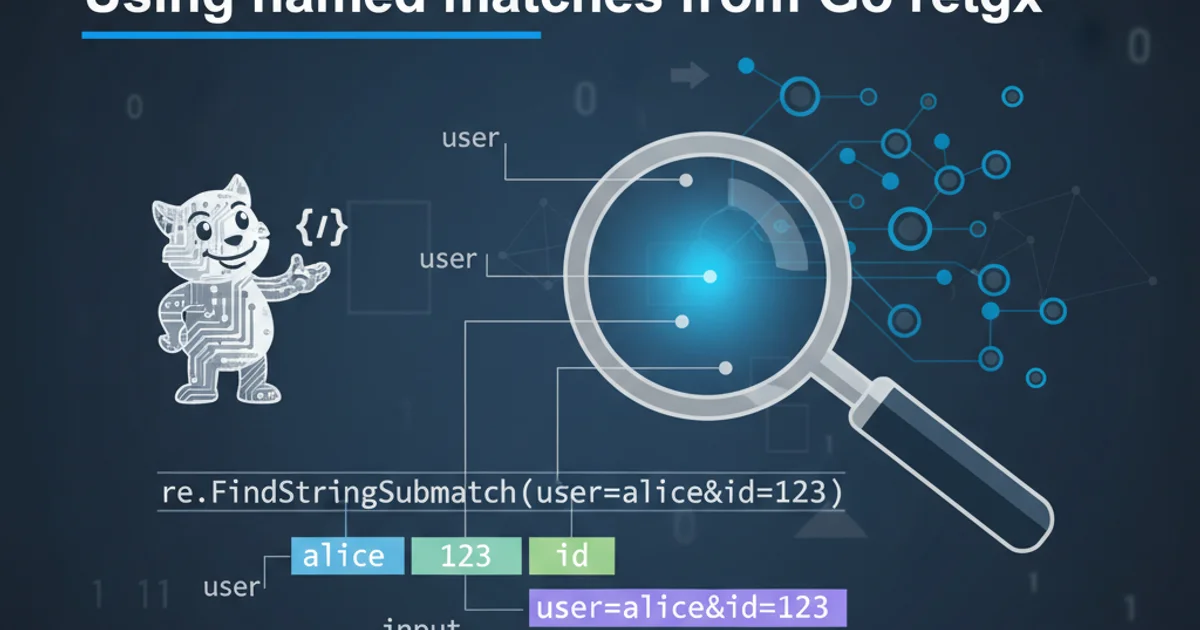
matches := logPattern.FindStringSubmatch(logLine)
if matches == nil {
fmt.Println("No match found.")
return
}
// Get the names of the capture groups
subexpNames := logPattern.SubexpNames()
// Create a map to store named matches
result := make(map[string]string)
for i, name := range subexpNames {
// The first element (index 0) is the full match, which has an empty name
if i != 0 && name != "" {
result[name] = matches[i]
}
}
fmt.Printf("Parsed Log Line:\n")
fmt.Printf(" Timestamp: %s\n", result["timestamp"])
fmt.Printf(" Level: %s\n", result["level"])
fmt.Printf(" Message: %s\n", result["message"])
// Example with a different log line
logLineError := "2023-10-27 14:35:05 [ERROR] Database connection failed."
matchesError := logPattern.FindStringSubmatch(logLineError)
if matchesError != nil {
for i, name := range subexpNames {
if i != 0 && name != "" {
result[name] = matchesError[i]
}
}
fmt.Printf("\nParsed Error Log Line:\n")
fmt.Printf(" Timestamp: %s\n", result["timestamp"])
fmt.Printf(" Level: %s\n", result["level"])
fmt.Printf(" Message: %s\n", result["message"])
}
}
In the example above, regexp.MustCompile compiles the regular expression. The FindStringSubmatch method returns a slice of strings, where the first element is the entire match, and subsequent elements are the captured groups. To associate these captured strings with their names, we use logPattern.SubexpNames(), which returns a slice of strings containing the names of the capture groups in order. The first element of SubexpNames is an empty string (representing the full match), followed by the names of the named groups, and then empty strings for any unnamed groups.
FindStringSubmatch returns nil before attempting to access elements of the matches slice. A nil return indicates that no match was found, preventing a runtime panic.Benefits and Best Practices
Using named capture groups offers several advantages:
- Readability: Code becomes much easier to understand when you refer to
result["timestamp"]instead ofmatches[1]. This is especially true for complex regex patterns with many groups. - Maintainability: If you need to add or remove a capture group in the middle of your regex, the numerical indices of subsequent groups would shift, requiring changes throughout your code. Named groups are immune to such shifts.
- Self-Documentation: The names themselves serve as documentation for what each part of the regex is intended to capture.
Best Practices:
- Choose descriptive names: Just like variable names, good group names improve clarity.
- Handle non-matches: Always check for
nilresults fromFindStringSubmatchor similar functions. - Compile once: For performance, compile your regular expressions once using
regexp.MustCompile(orregexp.Compilewith error handling) and reuse the compiled*regexp.Regexpobject.
regexp package supports named capture groups, it's important to note that not all regex engines use the (?P<name>pattern) syntax. Other common syntaxes include (?<name>pattern) or (?'name'pattern).