How can I display a character above U+FFFF?
Categories:
Displaying Unicode Characters Beyond U+FFFF

Explore the challenges and solutions for correctly rendering supplementary Unicode characters (those above U+FFFF) in various programming environments and systems.
Unicode is a character encoding standard designed to support text from all of the world's writing systems. While many common characters fit within the Basic Multilingual Plane (BMP), which covers code points from U+0000 to U+FFFF, a significant number of characters, including many emojis, historical scripts, and less common symbols, reside in supplementary planes (U+10000 and above). Displaying these characters correctly can sometimes be a challenge, as older systems or software might not fully support their encoding or rendering.
Understanding Supplementary Characters and UTF-16
Supplementary characters are those with code points greater than U+FFFF. In UTF-16 encoding, characters in the BMP are represented by a single 16-bit code unit. However, supplementary characters require two 16-bit code units, known as a 'surrogate pair'. The first code unit is a 'high surrogate' (U+D800 to U+DBFF), and the second is a 'low surrogate' (U+DC00 to U+DFFF). Incorrect handling of these pairs is a common source of display issues.
flowchart TD
A[Unicode Character] --> B{Code Point > U+FFFF?}
B -- Yes --> C[Requires Surrogate Pair]
C --> D["High Surrogate (U+D800-DBFF)"]
C --> E["Low Surrogate (U+DC00-DFFF)"]
D & E --> F[UTF-16 Representation]
B -- No --> G[Single 16-bit Code Unit]
G --> FFlowchart illustrating how Unicode characters are represented in UTF-16 based on their code point.
Common Pitfalls and Solutions
Many programming languages and environments have evolved to better handle supplementary characters, but issues can still arise. These often stem from:
- Incorrect String Length Calculation: Some functions might count code units instead of actual characters (grapheme clusters).
- Substring Operations: Slicing strings based on code unit indices can split surrogate pairs, leading to malformed characters.
- Font Support: The system or application must have a font installed that contains the glyphs for the specific supplementary characters being displayed.
- Legacy System Compatibility: Older operating systems, browsers, or libraries might not fully support the rendering of these characters.
Implementation Examples in Various Languages
Here's how different languages handle supplementary characters. The key is often to use functions that operate on Unicode code points or grapheme clusters rather than raw byte or code unit indices.
Python
# Python 3 handles Unicode characters correctly by default
char_above_ffff = "𠮷" # U+20BB7
print(f"Character: {char_above_ffff}")
print(f"Length (characters): {len(char_above_ffff)}") # Correctly 1
print(f"Code point: {ord(char_above_ffff)}")
# Iterating over characters
for c in "Hello 𠮷 World":
print(c, end=' ')
# Output: H e l l o 𠮷 W o r l d
JavaScript
// JavaScript's string length and charAt() can be problematic
let charAboveFfff = "𠮷"; // U+20BB7
console.log(`Character: ${charAboveFfff}`);
console.log(`Length (code units): ${charAboveFfff.length}`); // 2 (incorrect for character count)
console.log(`Code point (incorrect): ${charAboveFfff.charCodeAt(0).toString(16)}`); // d842 (high surrogate)
// Correct way to get character length and iterate
console.log(`Length (characters): [...charAboveFfff].length`); // 1
console.log(`Code point (correct): ${charAboveFfff.codePointAt(0).toString(16)}`); // 20bb7
// Iterating over characters using spread operator or for...of
for (let char of "Hello 𠮷 World") {
console.log(char);
}
Java
// Java handles supplementary characters well with appropriate methods
String charAboveFfff = "𠮷"; // U+20BB7
System.out.println("Character: " + charAboveFfff);
System.out.println("Length (code units): " + charAboveFfff.length()); // 2
System.out.println("Length (code points): " + charAboveFfff.codePointCount(0, charAboveFfff.length())); // 1
// Iterating over code points
for (int i = 0; i < charAboveFfff.length(); ) {
int codePoint = charAboveFfff.codePointAt(i);
System.out.print(Character.toChars(codePoint));
i += Character.charCount(codePoint);
}
System.out.println();
C#
// C# strings are UTF-16 internally, but provide methods for code point handling
string charAboveFfff = "𠮷"; // U+20BB7
Console.WriteLine($"Character: {charAboveFfff}");
Console.WriteLine($"Length (code units): {charAboveFfff.Length}"); // 2
// Correct way to iterate over Unicode scalar values (code points)
foreach (int codePoint in charAboveFfff.AsEnumerable().SelectMany(c => char.IsHighSurrogate(c) ? new int[] { char.ConvertToUtf32(c, charAboveFfff[charAboveFfff.IndexOf(c) + 1]) } : (char.IsLowSurrogate(c) ? new int[] { } : new int[] { c }))) {
Console.WriteLine($"Code Point: {codePoint:X4}");
}
// A simpler approach for iterating grapheme clusters (requires .NET 5+)
// using System.Globalization;
// StringInfo si = new StringInfo(charAboveFfff);
// Console.WriteLine($"Length (grapheme clusters): {si.LengthInTextElements}"); // 1
Ensuring Proper Font and Rendering
Even with correct encoding and string manipulation, characters won't display if the rendering environment lacks the necessary font glyphs. Modern operating systems and browsers typically come with extensive font sets, but for specialized characters (e.g., obscure historical scripts, less common emojis), you might need to:
- Specify a font: In web development, use CSS
font-familyto suggest fonts known to contain the glyphs. - Embed fonts: For web, use
@font-faceto embed web fonts that include the required characters. - Install fonts: On desktop systems, ensure the user has a font installed that supports the character set.
- Fallback mechanisms: Browsers and text renderers often have fallback mechanisms to try different fonts if the primary one doesn't contain a glyph.
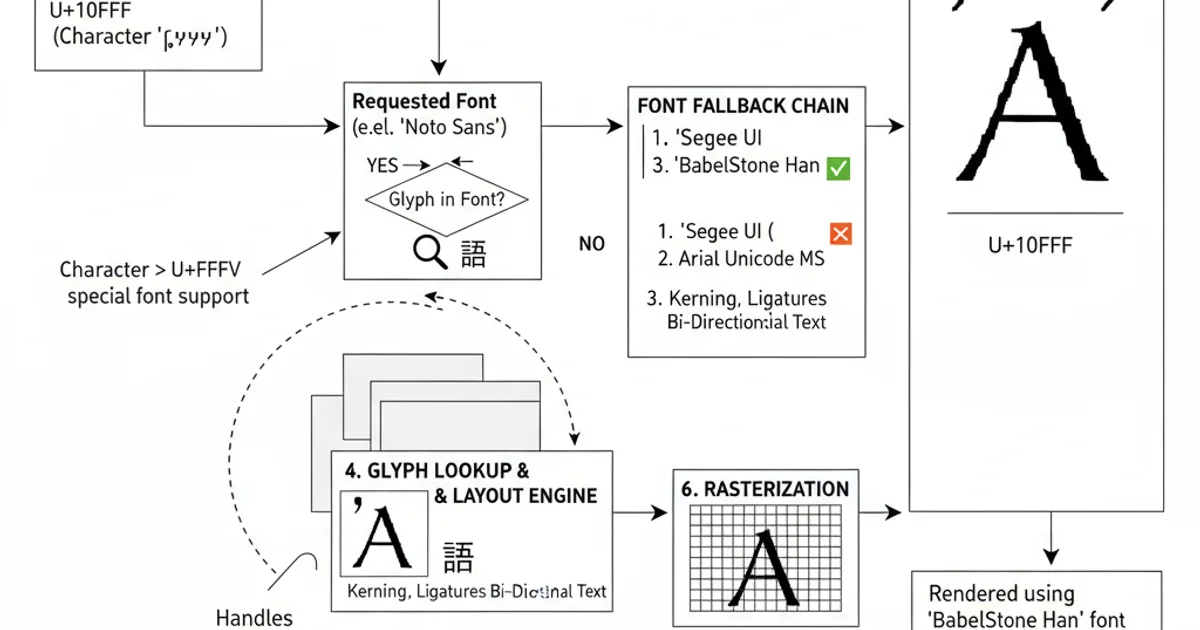
The Unicode rendering pipeline, emphasizing the role of fonts and fallback mechanisms.