Collections.defaultdict difference with normal dict
Categories:
Understanding Python's defaultdict vs. Standard dict

Explore the key differences between Python's collections.defaultdict and the built-in dict, and learn when to use each for more efficient and readable code.
Python's dict (dictionary) is a fundamental data structure for storing key-value pairs. However, when dealing with scenarios where you need to access a key that might not yet exist, the standard dict can lead to KeyError exceptions. This is where collections.defaultdict comes into play, offering a convenient way to handle missing keys by providing a default value or factory function.
The Problem with Missing Keys in Standard dict
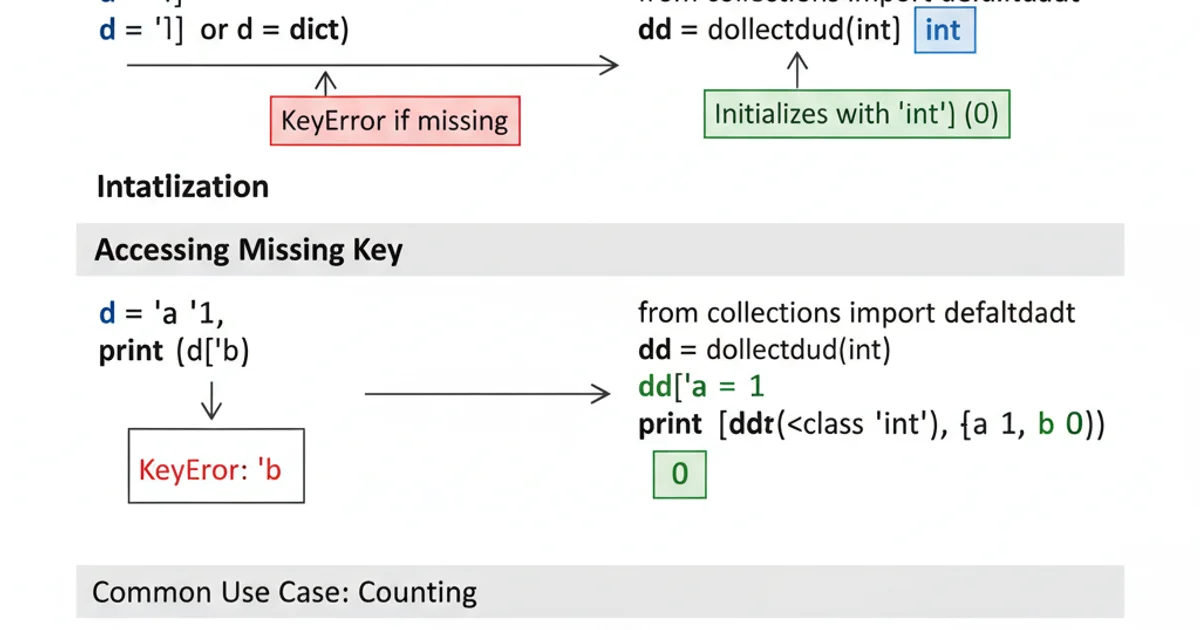
A standard Python dictionary raises a KeyError if you try to access a key that doesn't exist. This often necessitates explicit checks or try-except blocks, which can make your code more verbose, especially when accumulating data or counting occurrences.
my_dict = {}
# Attempting to access a non-existent key
try:
print(my_dict['non_existent_key'])
except KeyError as e:
print(f"KeyError: {e} - Key does not exist")
# To add to a list for a key that might not exist:
if 'fruits' not in my_dict:
my_dict['fruits'] = []
my_dict['fruits'].append('apple')
print(my_dict)
Demonstrating KeyError and manual handling in a standard dict.
flowchart TD
A[Start]
B{Access Key 'X' in dict?}
C{Key 'X' exists?}
D[Return Value for 'X']
E[Raise KeyError]
A --> B
B --> C
C -- Yes --> D
C -- No --> EFlowchart of key access in a standard Python dictionary.
Introducing collections.defaultdict
collections.defaultdict is a subclass of dict that overrides one method: __missing__. When you try to access a key that isn't in a defaultdict, it calls the default_factory (a function you provide during initialization) to supply a default value for that key, inserts it into the dictionary, and then returns it. This eliminates the need for explicit key existence checks.
from collections import defaultdict
# Using int as the default_factory for counting
counts = defaultdict(int)
words = ['apple', 'banana', 'apple', 'orange', 'banana', 'apple']
for word in words:
counts[word] += 1 # No KeyError, int() returns 0 by default
print(counts)
# Output: defaultdict(<class 'int'>, {'apple': 3, 'banana': 2, 'orange': 1})
# Using list as the default_factory for grouping
grouped_items = defaultdict(list)
data = [('fruit', 'apple'), ('vegetable', 'carrot'), ('fruit', 'banana'), ('vegetable', 'broccoli')]
for category, item in data:
grouped_items[category].append(item) # No KeyError, list() returns [] by default
print(grouped_items)
# Output: defaultdict(<class 'list'>, {'fruit': ['apple', 'banana'], 'vegetable': ['carrot', 'broccoli']})
Practical examples of defaultdict with int and list as default factories.
flowchart TD
A[Start]
B{Access Key 'X' in defaultdict?}
C{Key 'X' exists?}
D[Return Value for 'X']
E[Call default_factory]
F[Insert default value for 'X']
G[Return default value]
A --> B
B --> C
C -- Yes --> D
C -- No --> E
E --> F
F --> GFlowchart of key access in collections.defaultdict.
Key Differences and Use Cases
The primary difference lies in how missing keys are handled. A standard dict is strict and raises an error, while defaultdict is lenient and provides a default value. This makes defaultdict particularly useful for aggregation, grouping, and frequency counting tasks where you expect to add to or modify values associated with keys that might not initially be present.
A side-by-side comparison of dict and defaultdict.
default_factory is called without arguments to produce a default value. Common choices include int (for 0), list (for []), set (for {}), or even a custom function or lambda.When to Use Which
Use a standard dict when:
- You need strict control over key existence and want an error if a key is missing.
- You are primarily retrieving existing values or explicitly setting new ones.
- The default value logic is complex and better handled outside the dictionary's automatic behavior.
Use collections.defaultdict when:
- You are accumulating data (e.g., counting occurrences, grouping items).
- You want to avoid
KeyErrorand reduce boilerplate code for initializing new keys with a default value. - The default value is simple and can be generated by a zero-argument function (like
int,list,set).
list or set with defaultdict. If you modify the default value returned for a key, that modification persists for that key. This is usually the desired behavior, but it's important to understand it's not creating a copy of the default value each time.