How to understand Tornado gen.coroutine
Categories:
Understanding Tornado's gen.coroutine for Asynchronous Programming
Dive deep into Tornado's gen.coroutine decorator, a powerful tool for writing asynchronous Python code that is both readable and efficient. Learn its mechanics, benefits, and how to use it effectively.
Tornado is a Python web framework and asynchronous networking library, originally developed at FriendFeed. One of its core features for handling concurrency and non-blocking I/O is its gen module, particularly the gen.coroutine decorator. This decorator allows you to write asynchronous code that looks and feels synchronous, significantly improving readability and maintainability compared to traditional callback-based approaches. While modern Python has async/await, understanding gen.coroutine is crucial for working with older Tornado codebases or appreciating the evolution of Python's async capabilities.
The Evolution of Asynchronous Python
Before Python 3.5 introduced the async and await keywords, libraries like Tornado developed their own mechanisms for asynchronous programming. Tornado's gen.coroutine was a pioneering solution that leveraged Python's yield keyword to create coroutines. These coroutines could pause their execution, yield control back to the event loop, and resume later when an I/O operation completed, all without blocking the main thread.
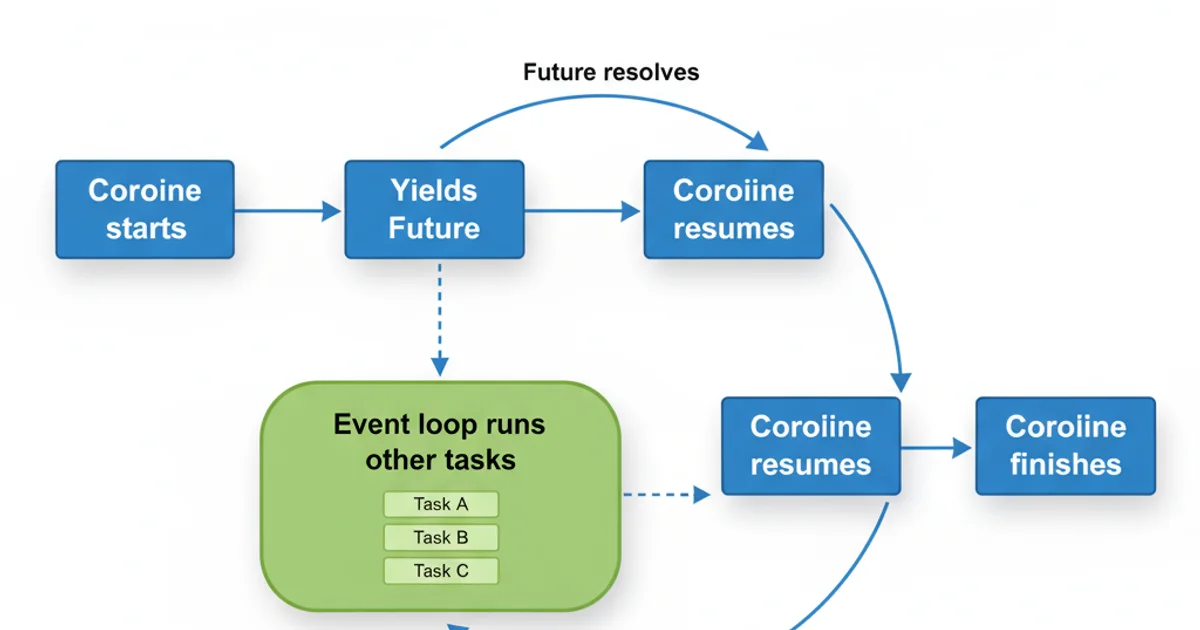
Asynchronous Flow with gen.coroutine
How gen.coroutine Works
The gen.coroutine decorator transforms a generator function into a coroutine that can be scheduled by Tornado's IOLoop. When a coroutine encounters a yield expression, it pauses its execution and returns a Future object (or a Task in older versions). The IOLoop then takes this Future and waits for it to complete. While waiting, the IOLoop can execute other tasks, ensuring that the application remains responsive. Once the Future resolves (e.g., an HTTP request completes, a database query returns), the IOLoop resumes the coroutine from where it left off, and the result of the Future is 'sent' back into the generator as the result of the yield expression.
import tornado.gen
import tornado.httpclient
import tornado.ioloop
@tornado.gen.coroutine
def fetch_url(url):
http_client = tornado.httpclient.AsyncHTTPClient()
try:
response = yield http_client.fetch(url)
print(f"Fetched {len(response.body)} bytes from {url}")
raise tornado.gen.Return(response.body)
except Exception as e:
print(f"Error fetching {url}: {e}")
raise tornado.gen.Return(None)
@tornado.gen.coroutine
def main():
print("Starting main coroutine...")
data = yield fetch_url("http://www.google.com")
if data:
print(f"Google homepage data length: {len(data)}")
else:
print("Failed to fetch Google homepage.")
print("Main coroutine finished.")
if __name__ == "__main__":
tornado.ioloop.IOLoop.current().run_sync(main)
Basic usage of gen.coroutine to fetch a URL asynchronously.
yield keyword in a gen.coroutine function is crucial. It signals a point where the coroutine can pause and allow the IOLoop to process other events. The expression after yield must be an awaitable object, typically a Future or a Task.Key Concepts and Best Practices
When working with gen.coroutine, several concepts are important to grasp:
yieldfor Awaitables: AlwaysyieldaFutureor aTask. Yielding anything else will not pause the coroutine in the intended asynchronous manner.gen.Return: In older Tornado versions (before Python 3.3'syield fromwas widely adopted), returning a value from agen.coroutinerequired raisingtornado.gen.Return(value). Withyield from(and laterasync/await), a simplereturn valueworks, butgen.Returnis still common in legacy code.- Error Handling: Use standard
try...exceptblocks within your coroutines. If an awaitedFutureraises an exception, it will be re-raised at theyieldpoint, allowing for normal error handling. IOLoop.run_sync(): To run a top-level coroutine and block until it completes, useIOLoop.current().run_sync(coroutine_function). This is common for entry points of applications or tests.- Compatibility with
async/await: Modern Tornado versions are fully compatible with Python's nativeasync/await. You can mix and matchgen.coroutinewithasync deffunctions, asgen.coroutinefunctions are themselves awaitable.
import tornado.gen
import tornado.ioloop
import asyncio # Python's native async library
@tornado.gen.coroutine
def old_style_coroutine():
print("Running old-style coroutine")
yield tornado.gen.sleep(1) # Simulate async work
print("Old-style coroutine finished")
raise tornado.gen.Return("Old Result")
async def new_style_coroutine():
print("Running new-style coroutine")
await asyncio.sleep(0.5) # Simulate async work
print("New-style coroutine finished")
return "New Result"
@tornado.gen.coroutine
def mixed_coroutine():
print("Starting mixed coroutine")
result_old = yield old_style_coroutine()
print(f"Received from old: {result_old}")
result_new = yield new_style_coroutine()
print(f"Received from new: {result_new}")
print("Mixed coroutine finished")
if __name__ == "__main__":
tornado.ioloop.IOLoop.current().run_sync(mixed_coroutine)
Demonstrating interoperability between gen.coroutine and async def.
gen.coroutine is still functional, for new code in Python 3.5+, it's generally recommended to use the native async def and await syntax for better readability and broader ecosystem compatibility.