What is the difference between CUDA core and CPU core?
Categories:
CUDA Cores vs. CPU Cores: Understanding the Core Differences

Explore the fundamental architectural and functional distinctions between CUDA Cores and CPU Cores, and learn why each excels in different computational tasks.
In the world of computing, 'cores' are fundamental processing units. However, not all cores are created equal. When discussing high-performance computing, especially in fields like AI, scientific simulation, and graphics rendering, the terms 'CPU core' and 'CUDA core' frequently arise. While both are designed to execute instructions, their architectures, design philosophies, and optimal use cases differ significantly. Understanding these differences is crucial for optimizing computational workloads and selecting the right hardware for specific tasks.
CPU Cores: The Versatile Generalists
A Central Processing Unit (CPU) is the 'brain' of a computer, responsible for executing most of the instructions of a computer program. CPU cores are designed for versatility and sequential processing. Each CPU core is a powerful, complex unit capable of handling a wide range of tasks, from operating system management to complex logical operations. They feature sophisticated control logic, large caches, and advanced branch prediction units to efficiently execute single-threaded tasks and manage diverse instruction sets.
flowchart TD
A[CPU Core] --> B{Complex Task?}
B -- Yes --> C[Sophisticated Control Logic]
B -- No --> D[General Purpose Execution]
C --> E[Large Cache]
D --> E
E --> F[Sequential Processing]
F --> G[Low Latency Access]
G --> H[Versatile Workloads]Architectural overview of a CPU core's processing flow.
CUDA Cores: The Parallel Specialists
CUDA (Compute Unified Device Architecture) cores are the processing units found within NVIDIA Graphics Processing Units (GPUs). Unlike CPU cores, CUDA cores are designed for massive parallelism. A single GPU can house thousands of these smaller, simpler cores. Each CUDA core is less powerful individually than a CPU core, with less complex control logic and smaller caches. However, their strength lies in their sheer numbers and their ability to execute many simple, identical operations simultaneously across large datasets. This architecture is ideal for tasks that can be broken down into many independent, parallel computations, such as matrix multiplications in AI, pixel shading in graphics, or Monte Carlo simulations.
flowchart TD
A[GPU] --> B[Many CUDA Cores]
B --> C[Simple Arithmetic Logic Unit (ALU)]
C --> D[Small Cache]
D --> E[Massive Parallel Processing]
E --> F[High Throughput]
F --> G[Data Parallel Workloads]
G --> H[Graphics Rendering & AI]Architectural overview of CUDA cores within a GPU.
Key Differences and Use Cases
The fundamental difference boils down to design philosophy: CPUs prioritize versatility and sequential performance, while GPUs prioritize throughput and parallel performance. This leads to distinct advantages for different types of workloads.
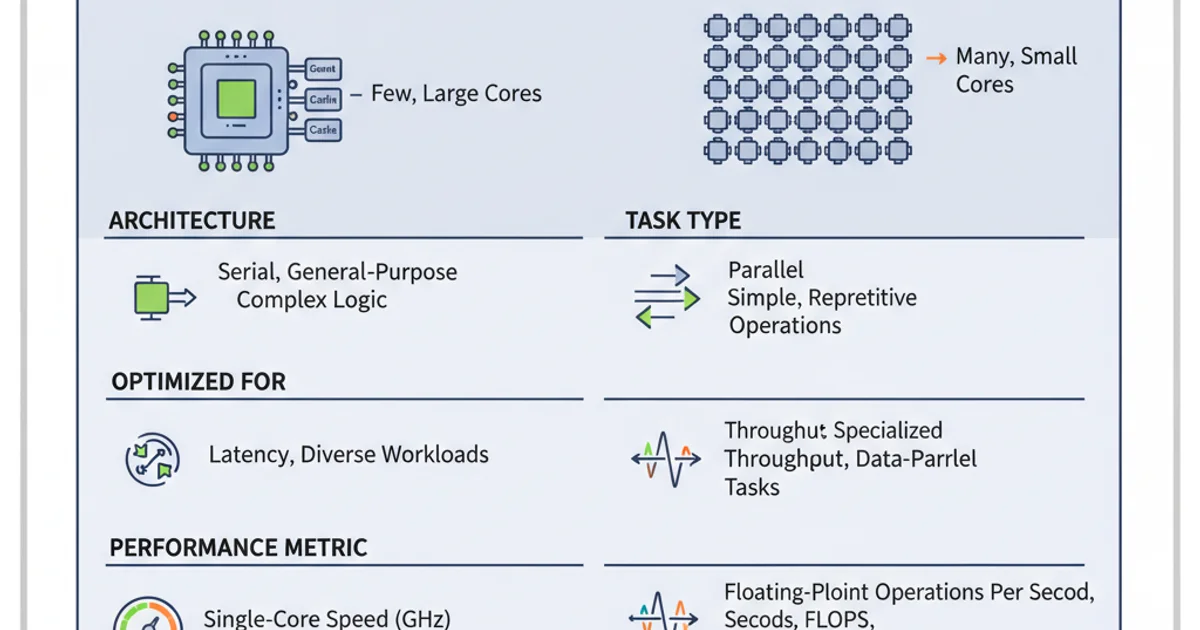
Comparison of CPU Cores and CUDA Cores
For example, a CPU might handle the overall game logic, AI decision-making for non-player characters, and network communication in a video game. Meanwhile, the GPU, with its CUDA cores, would be responsible for rendering every pixel on the screen, applying textures, and calculating lighting effects – tasks that involve millions of independent calculations performed in parallel.
Programming Model Differences
The way you program for these different architectures also varies. CPU programming often involves languages like C++, Java, or Python, utilizing standard libraries and operating system calls. GPU programming, particularly with CUDA cores, requires specialized programming models like NVIDIA's CUDA C/C++ or OpenCL, which allow developers to explicitly manage data transfer between the CPU and GPU and orchestrate parallel kernel execution across thousands of cores.
// Simple CPU-bound loop
for (int i = 0; i < N; ++i) {
result[i] = complex_calculation(data[i]);
}
// Simplified CUDA kernel for GPU (conceptual)
__global__ void simple_kernel(float* data, float* result, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
result[idx] = simple_calculation(data[idx]);
}
}
Conceptual difference between CPU and GPU (CUDA) programming paradigms.