Web scraping with Python
Categories:
Mastering Web Scraping with Python: A Comprehensive Guide

Unlock the power of data extraction from websites using Python. This guide covers essential libraries, ethical considerations, and practical techniques for effective web scraping.
Web scraping is the automated process of extracting data from websites. It's a powerful technique for gathering information, but it comes with responsibilities. This article will guide you through the fundamentals of web scraping using Python, focusing on popular libraries like requests and BeautifulSoup, and discussing ethical considerations and best practices.
Understanding the Basics: HTTP Requests and HTML Parsing
At its core, web scraping involves two main steps: making an HTTP request to a web server to retrieve the page's content, and then parsing that content (usually HTML) to extract the desired data. Python's requests library simplifies the first step, while BeautifulSoup excels at the second.
sequenceDiagram
participant Your_Script as Your Python Script
participant Web_Server as Web Server
Your_Script->>Web_Server: HTTP GET Request (URL)
Web_Server-->>Your_Script: HTTP Response (HTML/CSS/JS)
Your_Script->>Your_Script: Parse HTML (BeautifulSoup)
Your_Script->>Your_Script: Extract Data
Your_Script->>Your_Script: Store/Process DataSequence diagram illustrating the web scraping process.
import requests
from bs4 import BeautifulSoup
# 1. Make an HTTP GET request
url = 'http://quotes.toscrape.com/'
response = requests.get(url)
# Check if the request was successful
if response.status_code == 200:
# 2. Parse the HTML content
soup = BeautifulSoup(response.text, 'html.parser')
# Example: Find all quote texts
quotes = soup.find_all('span', class_='text')
for quote in quotes:
print(quote.get_text())
else:
print(f"Failed to retrieve page: {response.status_code}")
Basic web scraping example using requests and BeautifulSoup.
robots.txt file (e.g., http://example.com/robots.txt) before scraping to understand their scraping policies. Respecting these rules is crucial for ethical scraping.Advanced Techniques: Handling Dynamic Content and Pagination
Many modern websites use JavaScript to load content dynamically, meaning the initial HTML retrieved by requests might not contain all the data. For such cases, tools like Selenium or Playwright, which automate browser interactions, become necessary. Additionally, most websites paginate their content, requiring your scraper to navigate through multiple pages.
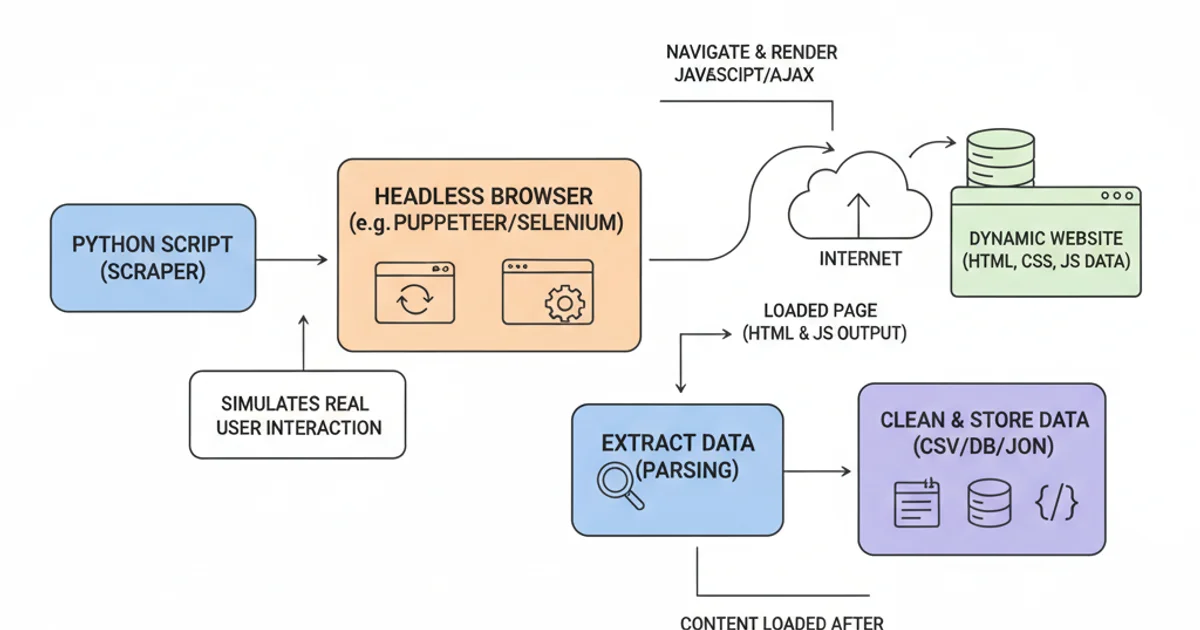
Workflow for scraping dynamic content using a headless browser.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
import time
# Setup Selenium WebDriver (ensure Chrome is installed)
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)
url = 'https://www.example.com/dynamic-content-page'
driver.get(url)
# Wait for dynamic content to load (adjust time as needed)
time.sleep(5)
# Now parse the page source with BeautifulSoup
soup = BeautifulSoup(driver.page_source, 'html.parser')
# Example: Find an element that was loaded dynamically
dynamic_element = soup.find('div', id='dynamic-data')
if dynamic_element:
print(f"Dynamic data: {dynamic_element.get_text()}")
driver.quit()
Scraping dynamic content using Selenium and a headless Chrome browser.
time.sleep()) and consider rotating user agents and IP addresses if necessary.Ethical Considerations and Best Practices
Web scraping, while powerful, must be conducted ethically and legally. Always prioritize respecting website terms of service, robots.txt directives, and server load. Good practices include identifying yourself with a custom User-Agent, implementing polite delays, and only scraping publicly available data that doesn't require authentication.
1. Check robots.txt
Before starting, visit yourwebsite.com/robots.txt to see which paths are disallowed for scraping. Respect these rules.
2. Review Terms of Service
Read the website's Terms of Service to understand any specific restrictions on data collection or automated access.
3. Be Polite
Implement delays between requests (time.sleep()) to avoid overwhelming the server. A common practice is 1-5 seconds between requests.
4. Identify Yourself
Set a custom User-Agent header in your requests that includes your contact information, so website administrators can reach you if there's an issue.
5. Handle Errors Gracefully
Implement error handling (e.g., try-except blocks) for network issues, HTTP errors, or unexpected page structures to make your scraper robust.