How to convert string to bytes in Python 3
Categories:
Mastering String to Bytes Conversion in Python 3

Learn the essential techniques for converting strings to bytes in Python 3, understanding character encodings, and handling common pitfalls.
In Python 3, strings and bytes are distinct and incompatible types. Strings (str) represent sequences of Unicode characters, while bytes (bytes) represent sequences of raw 8-bit values. This fundamental distinction is crucial for handling text data, especially when interacting with external systems like network sockets, file I/O, or databases, which typically operate on bytes. This article will guide you through the process of converting strings to bytes, focusing on the encode() method and the importance of character encodings.
Understanding Strings and Bytes
Before diving into conversion, it's vital to grasp the difference between str and bytes objects in Python 3. A str object is a sequence of Unicode code points, which are abstract numbers representing characters. A bytes object, on the other hand, is a sequence of integers in the range 0-255, representing raw binary data. The process of converting a string to bytes is called encoding, and converting bytes back to a string is called decoding.
flowchart LR
A["String (Unicode)"] -- "encode()" --> B["Bytes (Raw Binary)"]
B -- "decode()" --> A
subgraph Encoding Process
A --> C["Character Set (e.g., UTF-8)"]
C --> B
end
style A fill:#f9f,stroke:#333,stroke-width:2px
style B fill:#bbf,stroke:#333,stroke-width:2pxThe relationship between strings and bytes, illustrating encoding and decoding.
The encode() Method: Your Primary Tool
The most common and recommended way to convert a string to bytes in Python 3 is by using the string's built-in encode() method. This method takes an encoding as an argument and returns a bytes object. If no encoding is specified, Python 3 defaults to UTF-8, which is generally a good practice due to its widespread support and efficiency for most text.
# Basic string to bytes conversion using default UTF-8 encoding
my_string = "Hello, world!"
my_bytes = my_string.encode()
print(f"Original string: {my_string} (type: {type(my_string)})")
print(f"Encoded bytes: {my_bytes} (type: {type(my_bytes)})")
# Specifying an encoding explicitly
unicode_string = "你好世界"
utf8_bytes = unicode_string.encode('utf-8')
print(f"\nOriginal Unicode string: {unicode_string}")
print(f"Encoded UTF-8 bytes: {utf8_bytes}")
# Using a different encoding (e.g., 'latin-1')
# Note: 'latin-1' can only encode characters up to U+00FF
latin1_string = "Café"
latin1_bytes = latin1_string.encode('latin-1')
print(f"\nOriginal Latin-1 string: {latin1_string}")
print(f"Encoded Latin-1 bytes: {latin1_bytes}")
Examples of using the encode() method with and without specifying an encoding.
UTF-8. This makes your code more readable and prevents potential issues if the default encoding changes or if your code is run in an environment with a different default.Handling Encoding Errors
Not all characters can be represented in every encoding. For example, a character like '你好' (Chinese characters) cannot be encoded using 'ascii' because 'ascii' only supports characters from 0-127. When encode() encounters a character it cannot represent in the specified encoding, it raises a UnicodeEncodeError. You can control how these errors are handled using the errors argument.
problematic_string = "Hello, world! 你好"
# Default error handling (raises UnicodeEncodeError)
try:
ascii_bytes = problematic_string.encode('ascii')
except UnicodeEncodeError as e:
print(f"\nError (default): {e}")
# 'ignore' errors: characters that cannot be encoded are simply dropped
ignored_bytes = problematic_string.encode('ascii', errors='ignore')
print(f"\nEncoded (ignore errors): {ignored_bytes}")
# 'replace' errors: unencodable characters are replaced with a placeholder (e.g., '?')
replaced_bytes = problematic_string.encode('ascii', errors='replace')
print(f"Encoded (replace errors): {replaced_bytes}")
# 'xmlcharrefreplace': replaces with XML character references (e.g., 你)
xml_bytes = problematic_string.encode('ascii', errors='xmlcharrefreplace')
print(f"Encoded (xmlcharrefreplace errors): {xml_bytes}")
# 'backslashreplace': replaces with Python backslash escape sequences (e.g., \u4f60)
backslash_bytes = problematic_string.encode('ascii', errors='backslashreplace')
print(f"Encoded (backslashreplace errors): {backslash_bytes}")
Demonstrating different error handling strategies for encode().
errors='ignore' or errors='replace' can prevent exceptions, they can also lead to data loss or corruption. Use them cautiously and only when you understand the implications for your data integrity. UTF-8 is almost always the best choice for general text as it can encode virtually all Unicode characters.Common Encodings
Python supports a wide range of character encodings. Here are some of the most common ones you'll encounter:
'utf-8': The most common and recommended encoding for web and general text. It's a variable-width encoding that can represent all Unicode characters.'latin-1'(ISO-8859-1): A single-byte encoding that covers most Western European languages. It's often used in older systems or protocols whereUTF-8wasn't available.'ascii': A 7-bit encoding that covers English letters, numbers, and basic symbols. It's a subset ofUTF-8andlatin-1.'cp1252': A Windows-specific encoding, similar tolatin-1but with some additional characters.
Choosing the correct encoding is paramount. If you encode with one encoding and try to decode with another, you will likely get a UnicodeDecodeError or garbled text (mojibake).
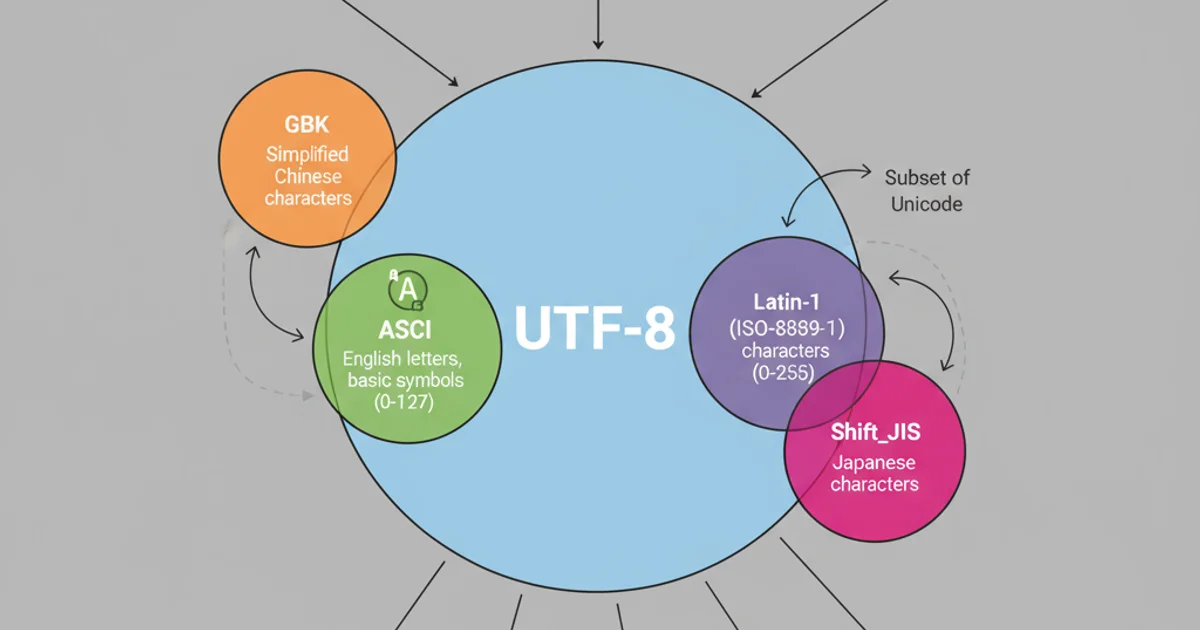
Visualizing the scope of common character encodings.
By understanding the distinction between strings and bytes, and mastering the encode() method with proper error handling, you can confidently manage text data in your Python 3 applications.