What is difference between primary index and secondary index exactly?
Primary vs. Secondary Indexes: Understanding Database Performance

Explore the fundamental differences between primary and secondary indexes in relational databases, their impact on query performance, and when to use each effectively.
Indexes are crucial for optimizing database query performance. Without them, a database system would have to scan every row in a table to find the data you're looking for, a process known as a full table scan. This can be incredibly slow for large tables. Indexes provide a quick lookup mechanism, much like the index in a book, allowing the database to jump directly to the relevant data.
While all indexes serve the purpose of speeding up data retrieval, primary and secondary indexes differ significantly in their structure, purpose, and impact on data storage and performance. Understanding these distinctions is key to designing efficient database schemas and optimizing your applications.
What is a Primary Index?
A primary index is a special type of index that is directly tied to the primary key of a table. Every table can have at most one primary key, and consequently, at most one primary index. The primary key uniquely identifies each record in a table, and the primary index enforces this uniqueness and provides a fast way to access rows based on their primary key value.
Key characteristics of a primary index:
- Uniqueness: It enforces the uniqueness constraint of the primary key. No two rows can have the same primary key value.
- Non-nullability: Primary key columns cannot contain
NULLvalues. - Clustered vs. Non-clustered: In many database systems (like SQL Server and MySQL's InnoDB engine), the primary index is a clustered index. This means the physical order of the data rows on disk is the same as the logical order of the primary key. When you query by the primary key, the database can directly navigate to the physical location of the data. In other systems (like Oracle), primary indexes are typically non-clustered, meaning the index stores pointers to the actual data rows, which are stored separately.
- Automatic Creation: When you define a primary key for a table, the database system automatically creates a primary index for it.
- Fast Lookups: Provides the fastest way to retrieve a single row or a range of rows based on the primary key.
erDiagram
CUSTOMER ||--o{ ORDER : places
CUSTOMER {
INT CustomerID PK "Primary Key"
VARCHAR(255) FirstName
VARCHAR(255) LastName
}
ORDER {
INT OrderID PK "Primary Key"
INT CustomerID FK "Foreign Key"
DATE OrderDate
}Entity-Relationship Diagram showing Customer and Order tables with Primary Keys
What is a Secondary Index?
A secondary index (also known as a non-clustered index in some systems) is an index created on one or more columns that are not the primary key. You can have multiple secondary indexes on a single table. They are used to speed up queries that filter or sort data based on these non-primary key columns.
Key characteristics of a secondary index:
- Optional: You explicitly create secondary indexes based on your query patterns.
- Multiple per Table: A table can have many secondary indexes.
- Non-unique (typically): Secondary indexes can be unique or non-unique. If unique, they enforce uniqueness on the indexed column(s). If non-unique, multiple rows can have the same value in the indexed column(s).
- Always Non-clustered: Secondary indexes store pointers to the actual data rows (or to the primary key in clustered index scenarios). This means retrieving data using a secondary index often involves an extra step: first finding the primary key (or row ID) in the secondary index, then using that to locate the actual data row.
- Trade-offs: While they speed up
SELECTqueries, secondary indexes add overhead toINSERT,UPDATE, andDELETEoperations because the index structure must also be updated. They also consume additional disk space.
graph TD
A[Query: SELECT * FROM Users WHERE Email = '...'] --> B{Secondary Index on Email}
B --> C{Find Primary Key for Email}
C --> D{Primary Index Lookup (Clustered)}
D --> E[Retrieve Full Row Data]Data retrieval flow using a secondary index (assuming a clustered primary index)
Key Differences Summarized
The table below highlights the core distinctions between primary and secondary indexes.
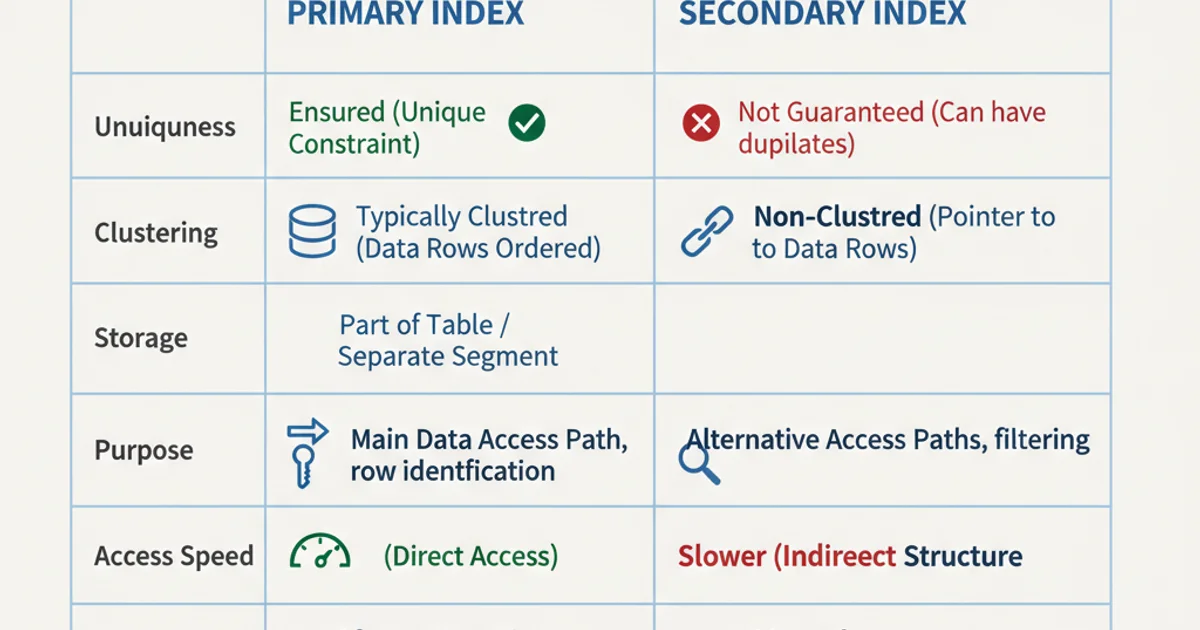
Comparison of Primary vs. Secondary Indexes
When to Use Which?
Choosing the right type of index is crucial for database performance.
Use a Primary Index when:
- You need to uniquely identify each row in a table.
- You frequently query rows by their unique identifier.
- You need to enforce data integrity and prevent duplicate records.
Use Secondary Indexes when:
- You frequently filter or sort data based on columns other than the primary key.
- You have columns that are often used in
WHEREclauses,JOINconditions, orORDER BYclauses. - You need to enforce uniqueness on a column or combination of columns that is not the primary key (unique secondary index).
- You are willing to accept some overhead on write operations for faster read operations.
Practical Examples (MySQL/Oracle)
Let's look at how primary and secondary indexes are defined and used in common database systems.
MySQL (InnoDB)
-- Create a table with a primary key (which automatically creates a clustered primary index)
CREATE TABLE Products (
ProductID INT PRIMARY KEY AUTO_INCREMENT,
ProductName VARCHAR(255) NOT NULL,
Category VARCHAR(100),
Price DECIMAL(10, 2)
);
-- Create a secondary index on the 'Category' column
CREATE INDEX idx_category ON Products (Category);
-- Create a unique secondary index on 'ProductName' to ensure uniqueness
CREATE UNIQUE INDEX uix_productname ON Products (ProductName);
-- Example query benefiting from primary index
SELECT * FROM Products WHERE ProductID = 123;
-- Example query benefiting from secondary index
SELECT ProductID, ProductName FROM Products WHERE Category = 'Electronics' ORDER BY ProductName;
Oracle Database
-- Create a table with a primary key (which automatically creates a non-clustered primary index)
CREATE TABLE Employees (
EmployeeID NUMBER PRIMARY KEY,
FirstName VARCHAR2(100),
LastName VARCHAR2(100),
DepartmentID NUMBER,
HireDate DATE
);
-- Create a secondary index on the 'DepartmentID' column
CREATE INDEX idx_department ON Employees (DepartmentID);
-- Create a unique secondary index on 'FirstName' and 'LastName' combination
CREATE UNIQUE INDEX uix_employee_name ON Employees (FirstName, LastName);
-- Example query benefiting from primary index
SELECT FirstName, LastName FROM Employees WHERE EmployeeID = 456;
-- Example query benefiting from secondary index
SELECT EmployeeID, FirstName, LastName FROM Employees WHERE DepartmentID = 10 ORDER BY HireDate DESC;