Rolling mean with customized window with Pandas
Categories:
Rolling Mean with Custom Windows in Pandas
Learn how to apply rolling mean calculations in Pandas with flexible, customized window definitions, going beyond fixed-size windows.
The rolling mean, also known as a moving average, is a fundamental tool in time series analysis for smoothing data and identifying trends. Pandas provides powerful functionalities for calculating rolling statistics, but often, the standard fixed-size window isn't sufficient. This article explores how to implement rolling means with customized, non-fixed windows, allowing for more flexible and context-aware data analysis.
Understanding Rolling Windows in Pandas
Pandas' .rolling() method is the gateway to calculating rolling statistics. By default, it expects a fixed integer for the window parameter, representing the number of observations to include in each calculation. However, real-world data often requires more nuanced window definitions. For instance, you might want a window that expands over time, or one that is defined by a specific time duration rather than a count of rows.
import pandas as pd
import numpy as np
# Create a sample DataFrame
df = pd.DataFrame({
'value': np.random.rand(20) * 100
})
# Calculate a simple fixed-size rolling mean
df['rolling_mean_fixed'] = df['value'].rolling(window=3).mean()
print("Fixed-size rolling mean:\n", df.head())
Basic fixed-size rolling mean calculation
Customizing Windows with Time-Based Offsets
When working with time series data, it's often more intuitive to define rolling windows based on time durations rather than a fixed number of rows. Pandas allows this by passing a string offset alias (e.g., '3D' for 3 days, '7D' for 7 days, '2H' for 2 hours) to the window parameter, provided your DataFrame has a DatetimeIndex.
import pandas as pd
import numpy as np
# Create a DataFrame with a DatetimeIndex
dates = pd.date_range(start='2023-01-01', periods=20, freq='D')
df_time = pd.DataFrame({
'value': np.random.rand(20) * 100
}, index=dates)
# Calculate a rolling mean with a 3-day window
df_time['rolling_mean_3D'] = df_time['value'].rolling(window='3D').mean()
print("\nTime-based rolling mean (3D window):\n", df_time.head())
# Calculate a rolling mean with a 7-day window, minimum 1 observation
df_time['rolling_mean_7D_min1'] = df_time['value'].rolling(window='7D', min_periods=1).mean()
print("\nTime-based rolling mean (7D window, min_periods=1):\n", df_time.head())
Rolling mean with time-based window offsets
DatetimeIndex. If not, convert it using pd.to_datetime() or df.set_index().Dynamic Windows with Custom Functions
For scenarios where window sizes are not fixed by count or simple time offsets, you can implement truly dynamic windows. This typically involves iterating through the DataFrame or using apply with a custom function that determines the window for each point. While less performant than built-in methods, this offers maximum flexibility.
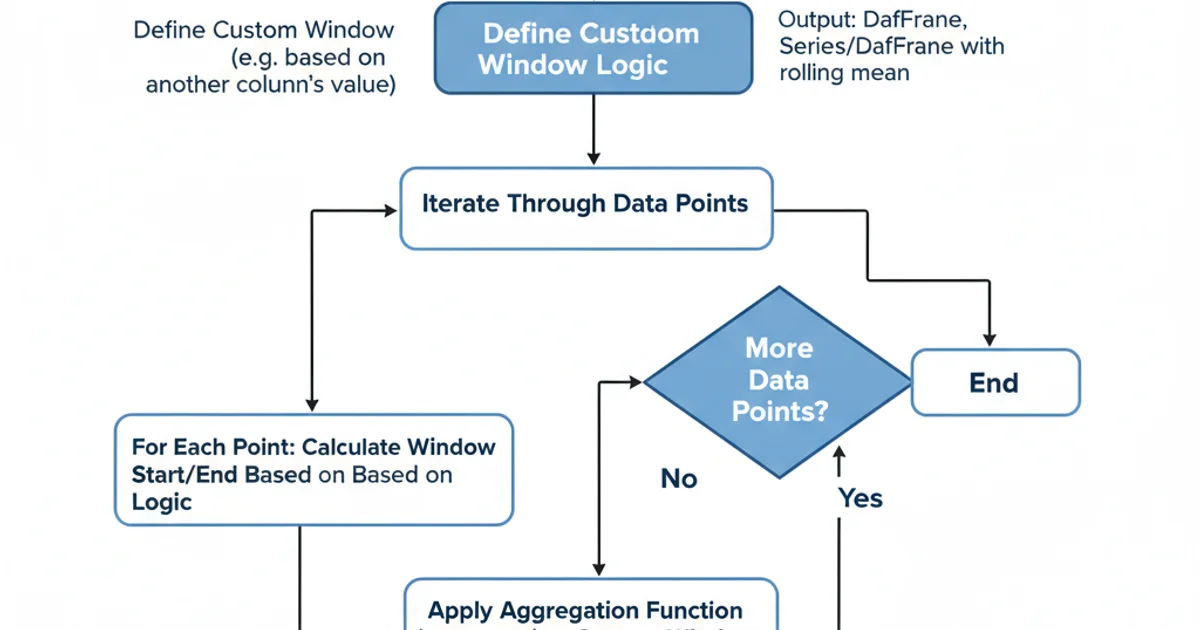
Process for applying dynamic rolling windows
import pandas as pd
import numpy as np
# Create a DataFrame with a 'window_size' column
df_dynamic = pd.DataFrame({
'value': np.random.rand(10) * 100,
'window_size': [2, 3, 2, 4, 3, 2, 5, 4, 3, 2] # Custom window size for each row
})
# Function to apply dynamic rolling mean (less efficient for large datasets)
def dynamic_rolling_mean(row):
idx = row.name
window_size = int(row['window_size'])
if idx < window_size - 1:
return np.nan # Not enough preceding data for the window
# Get the slice of data for the current window
window_data = df_dynamic.loc[idx - window_size + 1 : idx, 'value']
return window_data.mean()
# Apply the custom function row-wise
df_dynamic['rolling_mean_dynamic'] = df_dynamic.apply(dynamic_rolling_mean, axis=1)
print("\nDynamic rolling mean with custom window size per row:\n", df_dynamic)
Implementing a dynamic rolling mean with a custom function
df.apply() row-wise can be computationally expensive for very large DataFrames. For performance-critical applications, consider vectorized solutions or Numba if possible, or pre-calculating window bounds.Expanding Windows
An expanding window is a special type of customized window where the window size grows with each observation, starting from a minimum number of periods and including all preceding data points up to the current one. This is useful for calculating cumulative statistics or means that consider all historical data.
import pandas as pd
import numpy as np
# Create a sample DataFrame
df_expand = pd.DataFrame({
'value': np.random.rand(15) * 100
})
# Calculate an expanding mean, requiring at least 2 observations to start
df_expand['expanding_mean'] = df_expand['value'].expanding(min_periods=2).mean()
print("\nExpanding mean:\n", df_expand.head(7))
Calculating an expanding mean
min_periods parameter is crucial for both rolling() and expanding(). It specifies the minimum number of observations in a window required to have a value (otherwise, the result is NaN). This helps avoid misleading statistics from incomplete windows.