Difference between Fact table and Dimension table?
Categories:
Fact Tables vs. Dimension Tables: Understanding Data Warehouse Foundations
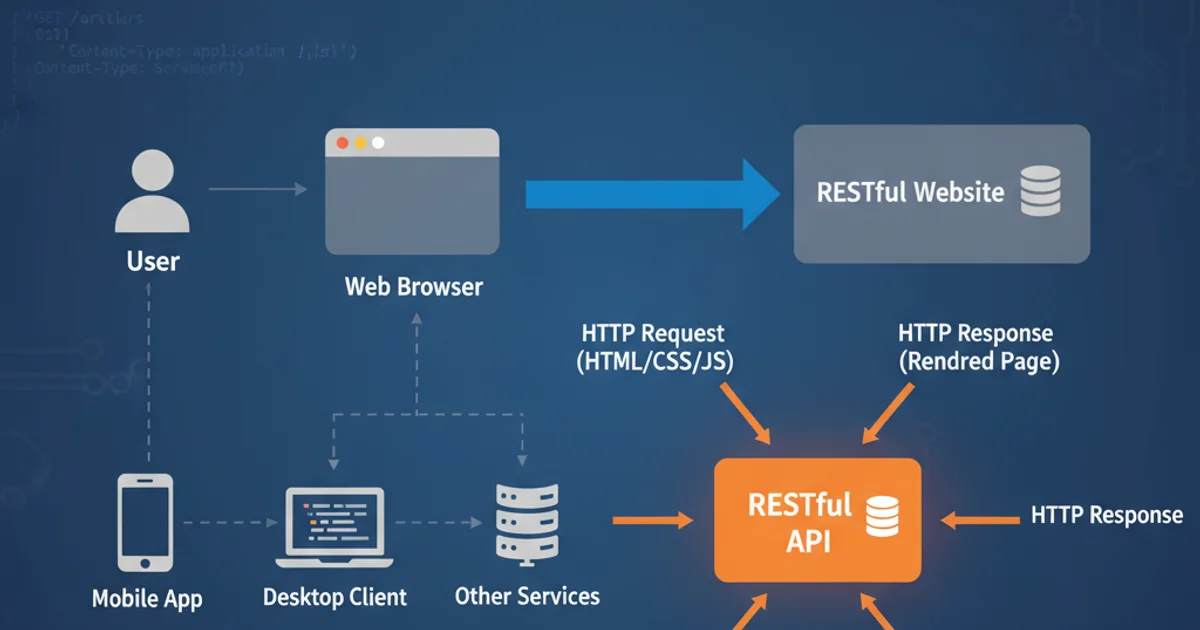
Explore the fundamental differences between fact tables and dimension tables, their roles in data warehousing, and how they enable powerful business intelligence.
In the realm of data warehousing and business intelligence, understanding the core components of a star schema or snowflake schema is crucial. At the heart of these designs are two primary types of tables: fact tables and dimension tables. These tables work in conjunction to store and organize vast amounts of data in a way that optimizes for analytical queries, rather than transactional processing. This article will delve into the distinct characteristics, purposes, and relationships of fact and dimension tables, providing a clear picture of their importance in a robust data warehouse architecture.
What is a Dimension Table?
Dimension tables are descriptive tables that contain attributes related to business entities. They provide context to the quantitative data stored in fact tables. Think of dimensions as the 'who, what, where, when, why, and how' of your business data. For example, in a sales data warehouse, a 'Product' dimension might describe products by their name, category, brand, color, and size. A 'Customer' dimension would describe customers by their name, address, age, and demographic information. Dimension tables are typically denormalized to improve query performance and are often relatively static, changing less frequently than fact tables.
What is a Fact Table?
Fact tables are central tables in a star or snowflake schema that store quantitative measurements or 'facts' about a business process. These measurements are typically numerical and additive, such as sales quantity, revenue, profit, or transaction counts. Fact tables contain foreign keys that link to the primary keys of dimension tables, establishing the relationships that allow for slicing and dicing data across various dimensions. They are usually very large, containing billions of rows, and grow rapidly as new business events occur. Fact tables are designed for efficient aggregation and analysis.
erDiagram
CUSTOMER ||--o{ SALES_FACT : "has"
PRODUCT ||--o{ SALES_FACT : "has"
DATE ||--o{ SALES_FACT : "has"
STORE ||--o{ SALES_FACT : "has"
SALES_FACT {
INT SalesFactID PK
INT CustomerID FK
INT ProductID FK
INT DateID FK
INT StoreID FK
DECIMAL Quantity
DECIMAL UnitPrice
DECIMAL TotalRevenue
}
CUSTOMER {
INT CustomerID PK
VARCHAR CustomerName
VARCHAR City
VARCHAR State
}
PRODUCT {
INT ProductID PK
VARCHAR ProductName
VARCHAR Category
VARCHAR Brand
}
DATE {
INT DateID PK
DATE FullDate
INT Year
INT Month
INT Day
}
STORE {
INT StoreID PK
VARCHAR StoreName
VARCHAR Region
}Example Star Schema showing a central SALES_FACT table linked to multiple dimension tables.
Key Differences and Relationship
The fundamental distinction lies in their purpose: dimensions provide context, while facts provide measurements. Fact tables are typically narrow and deep (many rows, few columns), optimized for aggregations. Dimension tables are wider and shallower (fewer rows, many columns), optimized for filtering and grouping. The relationship between them is crucial for analytical queries. A fact table will have multiple foreign keys, each pointing to a primary key in a different dimension table. This structure allows analysts to query 'Total Revenue by Product Category for Customers in New York in 2023', by joining the SALES_FACT table with the PRODUCT, CUSTOMER, and DATE dimensions.
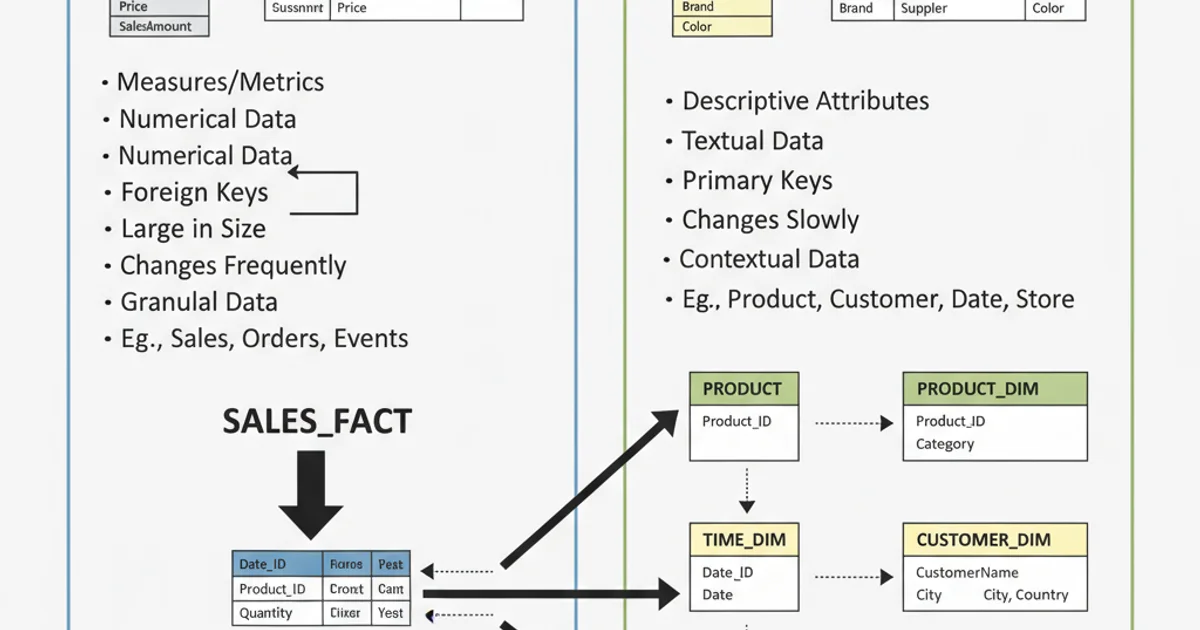
Comparison of Fact Table vs. Dimension Table Characteristics
Designing for Performance and Scalability
Effective data warehouse design hinges on correctly identifying facts and dimensions. A well-designed star schema, with its simple joins between a central fact table and surrounding dimension tables, offers excellent query performance. Snowflake schemas, which normalize dimensions into sub-dimensions, can reduce data redundancy but may introduce more complex joins, potentially impacting performance for certain queries. The choice between these depends on specific business requirements, data volume, and performance needs. Regardless of the schema type, the clear separation of descriptive attributes (dimensions) from measurable events (facts) is a cornerstone of efficient analytical systems.