SQL queries inside IN() clause
Leveraging SQL Queries within the IN() Clause for Dynamic Filtering
Explore the power and pitfalls of using subqueries inside SQL's IN() clause to create dynamic and flexible data filtering conditions.
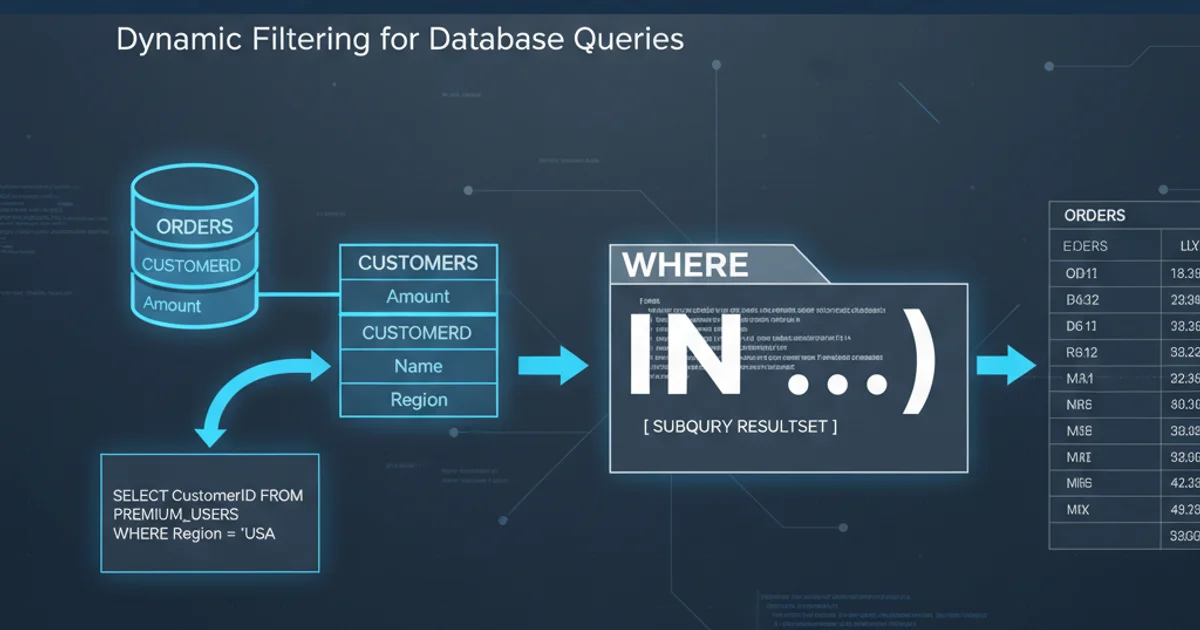
The IN() clause in SQL is a powerful tool for filtering results based on a list of values. While it's commonly used with static lists, its true flexibility shines when combined with subqueries. This allows you to dynamically generate the list of values for filtering, making your queries more adaptable and robust. This article will delve into how to effectively use SQL queries within the IN() clause, discuss common use cases, and highlight important considerations for performance and correctness.
Understanding the IN() Clause with Subqueries
At its core, the IN() clause checks if a value matches any value in a provided set. When you embed a subquery within IN(), the database first executes the subquery. The result of this subquery, which must be a single column of values, then becomes the set against which the outer query's filtering condition is evaluated. This dynamic generation of the comparison set is what makes this technique so versatile.
flowchart TD
A[Outer Query Execution] --> B{Evaluate WHERE Clause}
B --> C{Is value IN (Subquery Result)?}
C --> D[Execute Subquery]
D --> E[Return Single Column of Values]
E --> C
C -->|True| F[Include Row]
C -->|False| G[Exclude Row]Flow of execution for a query using a subquery in the IN() clause
SELECT
p.product_name,
p.price
FROM
products p
WHERE
p.category_id IN (
SELECT
c.category_id
FROM
categories c
WHERE
c.category_name = 'Electronics'
);
Basic example of a subquery in the IN() clause
Common Use Cases and Best Practices
Using subqueries with IN() is ideal for scenarios where the filtering criteria are not fixed but depend on other data in your database. This includes finding records related to a specific group, identifying items that have appeared in certain transactions, or filtering based on aggregated data. While powerful, it's crucial to consider performance. For very large result sets from the subquery, EXISTS or JOIN operations might offer better performance, especially if the subquery returns many rows or if the outer query is also very large.
IN() clause will raise an error. Also, be mindful of NULL values returned by the subquery, as they can lead to unexpected results (a value IN (1, 2, NULL) will evaluate to UNKNOWN if the value is not 1 or 2, effectively excluding it).SELECT
o.order_id,
o.order_date,
o.customer_id
FROM
orders o
WHERE
o.customer_id IN (
SELECT
c.customer_id
FROM
customers c
WHERE
c.registration_date >= '2023-01-01'
AND c.country = 'USA'
);
-- Alternative using JOIN for potentially better performance with large datasets
SELECT
o.order_id,
o.order_date,
o.customer_id
FROM
orders o
INNER JOIN
customers c ON o.customer_id = c.customer_id
WHERE
c.registration_date >= '2023-01-01'
AND c.country = 'USA';
Filtering orders based on customer registration criteria, with a JOIN alternative
Performance Considerations and Alternatives
While IN() with subqueries is convenient, it's not always the most performant option. Databases often optimize IN clauses by converting them into EXISTS or JOIN operations internally, but this isn't guaranteed. When the subquery returns a very large number of rows, or if the subquery itself is complex, performance can degrade. In such cases, explicitly using EXISTS or INNER JOIN can provide more predictable and often better performance, as they might allow the optimizer to choose more efficient execution plans.
graph TD
A[Query with IN Subquery] --> B{Optimizer Decision}
B --> C{Subquery Result Set Size}
C -->|Small| D[Execute as IN (list)]
C -->|Large| E[Convert to EXISTS or JOIN]
E --> F[Optimized Execution Plan]
D --> G[Result]
F --> GDatabase optimizer's decision process for IN() clause with subqueries
NOT IN() with subqueries that might return NULL values. If the subquery returns even a single NULL, the entire NOT IN() condition will evaluate to UNKNOWN for all rows, effectively returning an empty result set. Use NOT EXISTS or LEFT JOIN with IS NULL for reliable exclusion.