Foreign keys vs secondary keys
Foreign Keys vs. Secondary Keys: Understanding Database Relationships and Indexing
Explore the fundamental differences between foreign keys and secondary keys in relational databases, their roles in data integrity, performance, and how they are implemented.
In the realm of relational databases, understanding how data is organized, linked, and efficiently retrieved is paramount. Two terms that frequently arise in this context are 'foreign keys' and 'secondary keys'. While both play crucial roles in database design and operation, they serve distinct purposes. This article will demystify these concepts, explaining their definitions, functions, and practical applications, helping you design more robust and performant database systems.
What is a Foreign Key?
A foreign key is a column or a set of columns in one table that refers to the primary key (or sometimes a unique key) in another table. Its primary purpose is to establish and enforce a link between two tables, ensuring referential integrity. This means that a foreign key constraint prevents actions that would destroy links between tables, such as deleting a parent record that has child records referencing it, or inserting a child record that references a non-existent parent.
erDiagram
CUSTOMER ||--o{ ORDER : places
ORDER ||--|{ ORDER_ITEM : contains
PRODUCT ||--o{ ORDER_ITEM : includes
CUSTOMER {
INT customer_id PK
VARCHAR name
VARCHAR email
}
ORDER {
INT order_id PK
INT customer_id FK
DATE order_date
}
ORDER_ITEM {
INT order_item_id PK
INT order_id FK
INT product_id FK
INT quantity
}
PRODUCT {
INT product_id PK
VARCHAR product_name
DECIMAL price
}Entity-Relationship Diagram showing Foreign Key relationships
What is a Secondary Key (Index)?
A secondary key, more commonly referred to as a secondary index, is a data structure that improves the speed of data retrieval operations on a database table. Unlike primary keys, which uniquely identify each record and often dictate the physical storage order, secondary keys are created on non-primary key columns to facilitate faster lookups based on those columns. They do not enforce uniqueness by default, though unique secondary indexes can be created. The main goal of a secondary index is to avoid full table scans when querying data.
graph TD
A[User Query: SELECT * FROM Products WHERE category = 'Electronics']
A --> B{Database Engine}
B --> C{Check for Index on 'category' column}
C -- Yes --> D[Use Secondary Index to find relevant rows]
C -- No --> E[Perform Full Table Scan]
D --> F[Retrieve Data Quickly]
E --> G[Retrieve Data Slowly]
F --> H[Return Results]
G --> HHow a Secondary Index speeds up data retrieval
Key Differences and Their Impact
The fundamental distinction lies in their purpose: foreign keys are about data integrity and relationships, while secondary keys (indexes) are about performance. A foreign key defines a logical link and enforces rules to maintain that link. A secondary key is an optimization technique to speed up queries. While a foreign key column often benefits from having an index (which would be a secondary index if it's not the primary key), the index itself is not the foreign key; it's an enhancement to its performance.
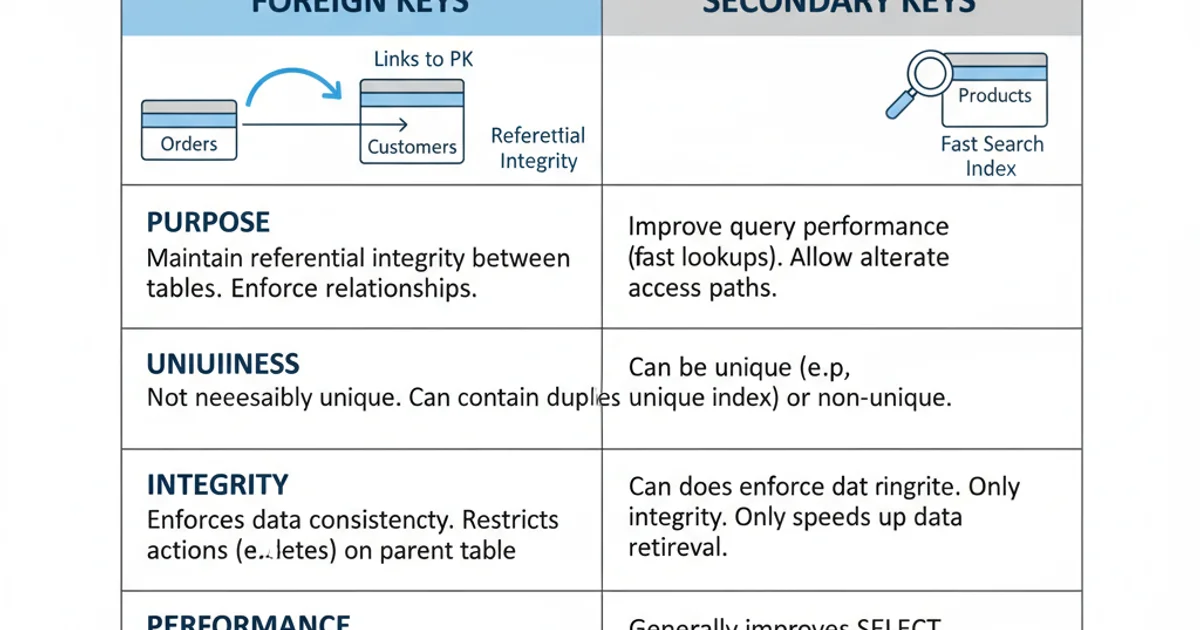
Comparison of Foreign Keys and Secondary Keys
-- Example of creating tables with a Foreign Key
CREATE TABLE Categories (
category_id INT PRIMARY KEY,
category_name VARCHAR(100) NOT NULL
);
CREATE TABLE Products (
product_id INT PRIMARY KEY,
product_name VARCHAR(255) NOT NULL,
price DECIMAL(10, 2),
category_id INT,
FOREIGN KEY (category_id) REFERENCES Categories(category_id)
);
-- Example of creating a Secondary Index
CREATE INDEX idx_product_name ON Products (product_name);
CREATE UNIQUE INDEX uidx_category_name ON Categories (category_name);
SQL examples demonstrating Foreign Key creation and Secondary Index creation.
In summary, foreign keys are declarative constraints that ensure the validity of relationships between tables, acting as guardians of your data's integrity. Secondary keys, on the other hand, are performance-enhancing structures that allow the database to locate data more quickly without scanning entire tables. Both are indispensable tools in a database designer's arsenal, but they address different aspects of database management.