How to merge two csv files not including duplicates
Categories:
Efficiently Merge CSV Files While Eliminating Duplicates in Bash
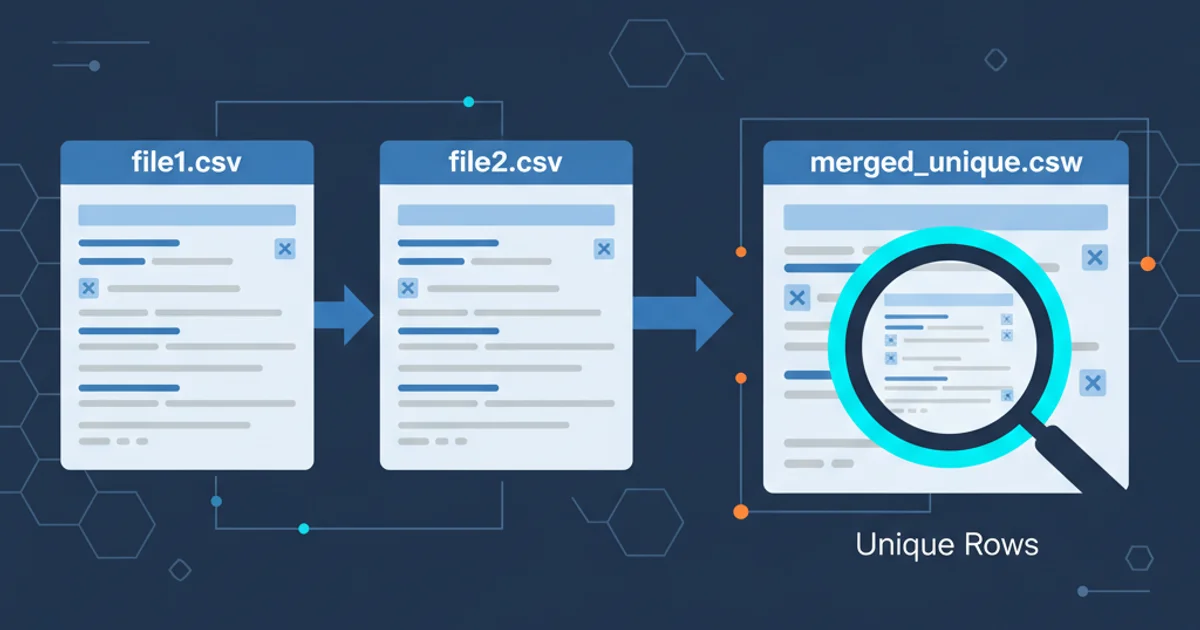
Learn how to combine multiple CSV files into a single, clean dataset, ensuring no duplicate rows are included, using powerful Bash command-line tools like cat, sort, uniq, awk, and sed.
Merging CSV files is a common data manipulation task, but often the challenge lies in handling duplicate entries. Simply concatenating files can lead to redundant data, which can skew analysis or cause issues in downstream processes. This article provides robust Bash solutions to merge two CSV files, ensuring that only unique rows are preserved in the final output. We'll explore different approaches, from basic concatenation with deduplication to more advanced methods that handle headers gracefully.
Understanding the Core Challenge: Duplicates and Headers
When merging CSV files, two primary concerns arise: identifying and removing duplicate rows, and correctly managing file headers. If both files have headers, simply concatenating them will result in a duplicate header row in the middle of your data. If you remove all duplicates indiscriminately, you might accidentally remove the header row itself if it matches a data row, or if both files have identical headers. Our solutions will address these issues to provide a clean, usable merged file.
flowchart TD
A[Start: Two CSV Files] --> B{Identify Headers?}
B -- Yes --> C[Extract Header from File 1]
B -- No --> D[Concatenate All Files]
C --> E[Concatenate Data (excluding headers)]
D --> F[Sort and Unique All Lines]
E --> F
F --> G[Prepend Header (if extracted)]
G --> H[End: Merged Unique CSV]Workflow for merging CSV files and removing duplicates, considering headers.
Method 1: Simple Concatenation and Deduplication (No Header Handling)
This method is straightforward and best suited for CSV files that either do not have headers or where you intend to manually add a header later. It concatenates all lines from both files and then uses sort and uniq to remove any identical lines. This approach treats every line as data, so if your files have headers, the header will be treated as a regular data line and might be removed if it's identical in both files.
cat file1.csv file2.csv | sort | uniq > merged_unique.csv
Concatenate, sort, and unique all lines from two CSV files.
Method 2: Preserving Headers with head, tail, sort, and uniq
A more robust approach involves extracting the header from one of the files, concatenating only the data rows (excluding headers), deduplicating the data, and then prepending the extracted header to the unique data. This ensures your final merged file has a single, correct header.
HEADER=$(head -n 1 file1.csv)
(tail -n +2 file1.csv; tail -n +2 file2.csv) | sort | uniq | sed "1i$HEADER" > merged_unique_with_header.csv
Extract header, merge data, deduplicate, and re-add header.
Let's break down this command:
HEADER=$(head -n 1 file1.csv): This command extracts the first line (header) fromfile1.csvand stores it in theHEADERshell variable.(tail -n +2 file1.csv; tail -n +2 file2.csv): This part usestail -n +2to print all lines starting from the second line (i.e., all data rows, excluding the header) from bothfile1.csvandfile2.csv. The parentheses create a subshell, allowing their output to be piped together.| sort | uniq: The combined data rows are then piped tosortto sort them, which is a prerequisite foruniqto work correctly, and thenuniqremoves any duplicate data rows.| sed "1i$HEADER": Finally, thesedcommand is used to insert the storedHEADERvariable as the first line (1i) of the unique data. Note the double quotes around"1i$HEADER"to allow shell variable expansion.> merged_unique_with_header.csv: The final output is redirected to a new file.
file1.csv and file2.csv are identical. If they differ, you might need to choose which header to keep or manually reconcile them before running the script.Method 3: Using awk for More Control and Efficiency
For larger files or more complex scenarios, awk provides a powerful and often more efficient way to handle merging and deduplication, especially when dealing with headers. awk can maintain an associative array (hash map) to track seen lines, making it very efficient for deduplication.
awk 'FNR==1 && NR!=1 {next} {a[$0]++} END {for (i in a) print i}' file1.csv file2.csv > merged_unique_awk.csv
Merge and deduplicate CSV files using awk, handling headers.
Let's dissect the awk command:
FNR==1 && NR!=1 {next}: This is the header handling logic.FNRis the current record number in the current file, andNRis the total record number across all files. This condition means: if it's the first line of a file (FNR==1) AND it's not the very first line of the first file being processed (NR!=1), then skip this line (next). This effectively skips headers from the second file onwards.{a[$0]++}: For every line ($0represents the entire line), it uses the line content as a key in an associative arrayaand increments its value. This effectively stores each unique line.END {for (i in a) print i}: After processing all files, theENDblock iterates through all unique keys (lines) stored in the arrayaand prints each one. The order of output is not guaranteed to be the original order, but it will be unique.
awk method is generally more memory-efficient for very large files compared to sort | uniq because it doesn't need to sort the entire dataset in memory. However, the output order is not guaranteed to be the original order of appearance, or sorted alphabetically, unless explicitly sorted afterwards.Choosing the Right Method
The best method depends on your specific needs:
- Method 1 (
cat | sort | uniq): Simplest for files without headers or when header preservation isn't critical. Fast for smaller files. - Method 2 (
head,tail,sort,uniq,sed): Recommended for most cases where you need to preserve a single header and deduplicate data. It's clear and effective. - Method 3 (
awk): Ideal for very large files where memory efficiency is a concern, or when you need more fine-grained control over line processing. Be aware of the unsorted output unless you pipe it tosortafterwards.