LOWER LIKE vs iLIKE
Categories:
LOWER(column) LIKE 'pattern' vs. iLIKE 'pattern': Performance and Usage in PostgreSQL
Explore the differences between LOWER(column) LIKE 'pattern' and iLIKE 'pattern' in PostgreSQL for case-insensitive pattern matching, focusing on performance implications and best practices.
When performing case-insensitive string searches in PostgreSQL, developers often encounter two primary methods: LOWER(column) LIKE 'pattern' and iLIKE 'pattern'. While both achieve similar results, their underlying mechanisms and performance characteristics can differ significantly. Understanding these differences is crucial for optimizing database queries, especially in applications dealing with large datasets.
Understanding Case-Insensitive Matching
Case-insensitive matching allows you to find strings regardless of their capitalization. For example, searching for 'apple' would match 'Apple', 'APPLE', or 'apple'. This is a common requirement in user-facing search functionalities where exact case matching might lead to missed results or a poor user experience.
LOWER(column) LIKE 'pattern'
This approach involves applying the LOWER() function to the column's value before comparing it with a lowercase pattern using the standard LIKE operator. The LOWER() function converts all characters in the string to their lowercase equivalent. This method is standard SQL and is portable across many database systems.
SELECT * FROM products WHERE LOWER(product_name) LIKE 'apple%';
Example of using LOWER() with LIKE for case-insensitive search.
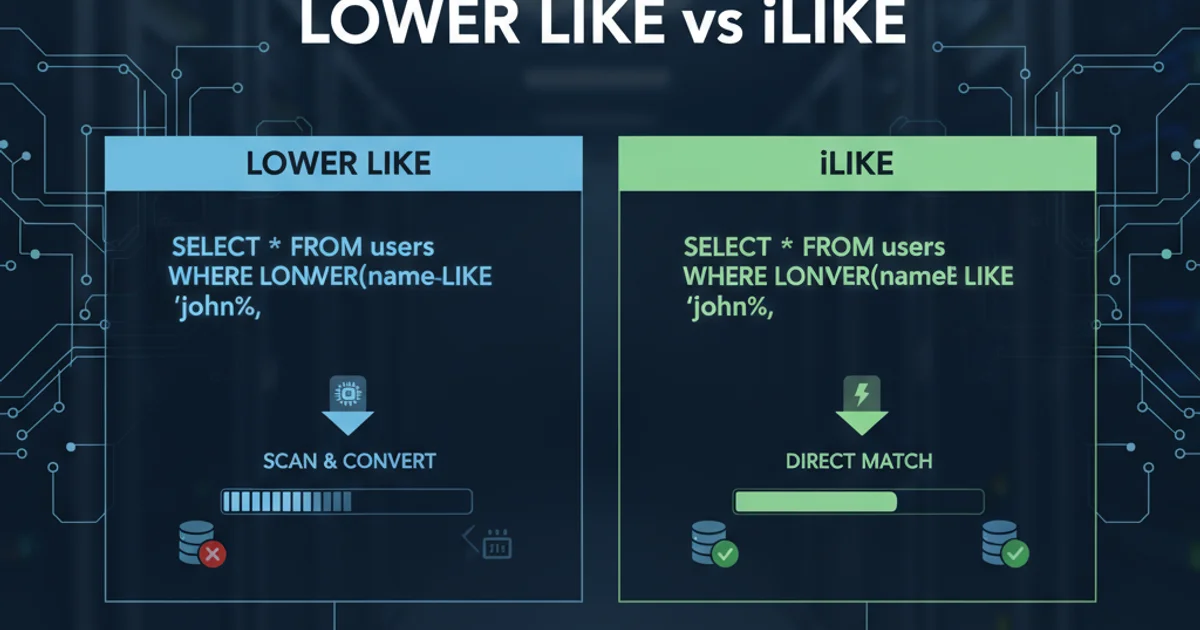
LOWER(column) LIKE 'pattern' is its impact on index usage. Applying a function to a column in the WHERE clause typically prevents the database from using a standard B-tree index on that column, leading to a full table scan. This can severely degrade performance on large tables.iLIKE 'pattern'
PostgreSQL provides the iLIKE operator as a non-standard, case-insensitive alternative to LIKE. It performs pattern matching similar to LIKE but ignores case differences. This operator is a PostgreSQL extension and offers a more concise and often more performant way to achieve case-insensitive searches within PostgreSQL.
SELECT * FROM products WHERE product_name ILIKE 'apple%';
Example of using ILIKE for case-insensitive search in PostgreSQL.
iLIKE operator can leverage indexes, specifically expression indexes or case-insensitive collations, to improve performance. This is a key advantage over LOWER(column) LIKE 'pattern'.Performance Comparison and Indexing Strategies
The performance difference between LOWER(column) LIKE 'pattern' and iLIKE 'pattern' primarily stems from their ability to utilize indexes. Let's visualize the query execution flow for both scenarios.
flowchart TD
A[Start Query] --> B{Condition: LOWER(col) LIKE 'pattern'}
B --> C{Apply LOWER() to each row}
C --> D{Compare with pattern}
D --> E[Full Table Scan]
E --> F[Return Results]
A --> G{Condition: col ILIKE 'pattern'}
G --> H{Check for suitable index (e.g., expression index)}
H --> |Index Found| I[Index Scan]
H --> |No Index / Not Usable| J[Full Table Scan]
I --> F
J --> FQuery Execution Flow for LOWER() LIKE vs. ILIKE
As the diagram illustrates, LOWER() LIKE almost always results in a full table scan because the function application on the column prevents standard index usage. iLIKE, however, can benefit from specialized indexes.
Optimizing iLIKE with Indexes
To make iLIKE perform efficiently, you can create a functional (or expression) index on the lowercase version of your column. This index stores the lowercase values, allowing iLIKE to perform an index scan.
CREATE INDEX idx_products_product_name_lower ON products (LOWER(product_name));
Creating an expression index for case-insensitive searches.
Alternatively, for PostgreSQL 12 and later, you can use case-insensitive collations. This allows you to define a column or an index with a collation that inherently handles case insensitivity, making LIKE (and iLIKE) case-insensitive by default for that column without needing LOWER() or expression indexes.
CREATE TABLE products_ci (
id SERIAL PRIMARY KEY,
product_name VARCHAR(255) COLLATE "en_US_POSIX_CI" -- Example of a case-insensitive collation
);
-- Or create an index with a collation
CREATE INDEX idx_products_product_name_ci ON products (product_name COLLATE "en_US_POSIX_CI");
Using case-insensitive collations for columns or indexes.
"en_US_POSIX_CI" or similar) might vary based on your system and PostgreSQL version.Conclusion and Best Practices
For PostgreSQL users, iLIKE is generally the preferred method for case-insensitive pattern matching due to its conciseness and potential for better performance through index utilization. While LOWER(column) LIKE 'pattern' is more portable, its performance overhead on large datasets often makes it a less optimal choice in PostgreSQL.
1. Prioritize iLIKE in PostgreSQL
Always use iLIKE for case-insensitive pattern matching in PostgreSQL queries unless portability to other SQL databases is a strict requirement.
2. Create Expression Indexes
For frequently queried columns using iLIKE, create an expression index on LOWER(column_name) to significantly improve query performance.
3. Consider Case-Insensitive Collations
If using PostgreSQL 12+, explore case-insensitive collations for columns that require frequent case-insensitive searches, as this can simplify queries and indexing.
4. Test Performance
Always test the performance of your queries with EXPLAIN ANALYZE to understand the execution plan and identify bottlenecks, especially after implementing indexing strategies.