How are iloc and loc different?
Categories:
Pandas iloc vs. loc: Mastering Dataframe Indexing
Understand the fundamental differences between iloc and loc in Pandas for precise and efficient data selection and manipulation in your DataFrames.
Pandas DataFrames are powerful tools for data analysis in Python. A core aspect of working with DataFrames is selecting and filtering data, and for this, Pandas provides two primary, yet distinct, indexers: iloc and loc. While both are used for data selection, they operate on entirely different principles – integer-location based indexing versus label-based indexing. Confusing them can lead to unexpected results and errors. This article will demystify iloc and loc, providing clear explanations and practical examples to help you master DataFrame indexing.
Understanding loc: Label-based Indexing
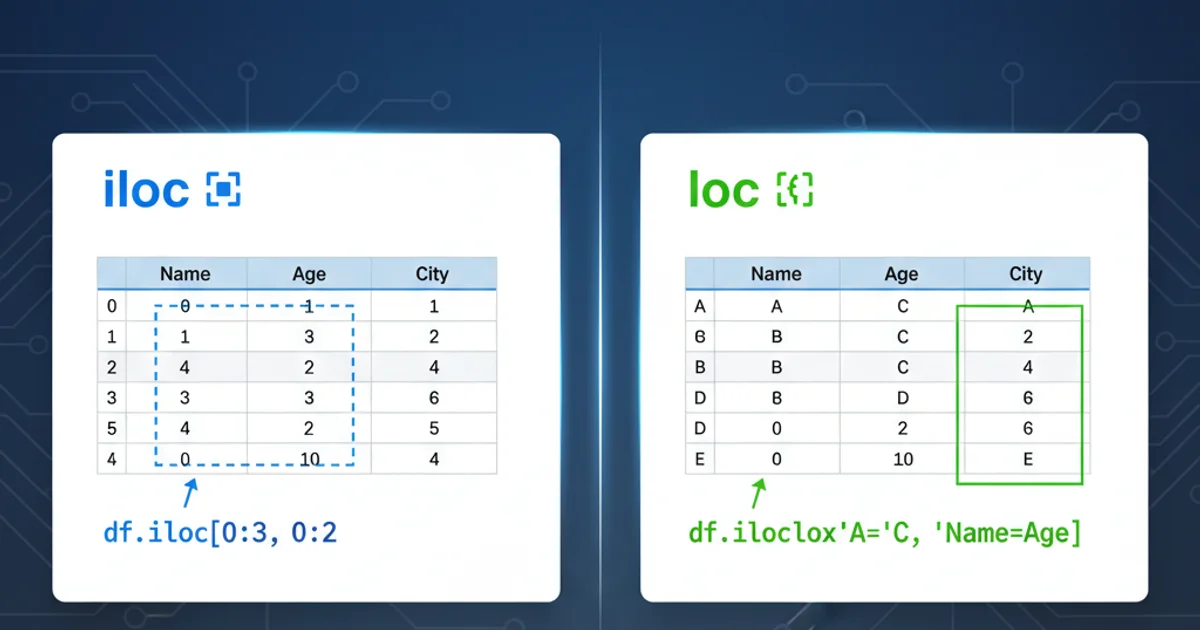
loc is primarily used for label-based indexing. This means you select data based on the labels of rows and columns, not their integer positions. When using loc, you provide the actual row and column labels (names) that you want to retrieve. It can accept a single label, a list of labels, a slice of labels, or a boolean array.
import pandas as pd
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],
'Age': [24, 27, 22, 32, 29],
'City': ['New York', 'Los Angeles', 'Chicago', 'Houston', 'Phoenix'],
'Salary': [70000, 80000, 60000, 90000, 75000]
}
df = pd.DataFrame(data, index=['a', 'b', 'c', 'd', 'e'])
print("Original DataFrame:")
print(df)
# Select row with label 'c'
print("\nRow 'c' using loc:")
print(df.loc['c'])
# Select rows 'a' to 'c' (inclusive) and columns 'Name' and 'City'
print("\nRows 'a' through 'c', columns 'Name' and 'City' using loc:")
print(df.loc['a':'c', ['Name', 'City']])
# Select rows where Age > 25 and column 'Salary'
print("\nRows where Age > 25, column 'Salary' using loc:")
print(df.loc[df['Age'] > 25, 'Salary'])
Examples of using loc for label-based indexing.
loc, both the start and end labels are inclusive. This is a key difference from standard Python list slicing, which is exclusive of the end index.Understanding iloc: Integer-location based Indexing
iloc is used for integer-location based indexing. This means you select data based on the integer positions of rows and columns, similar to how you would index a Python list or NumPy array. The first row has an index of 0, the second 1, and so on. iloc also accepts a single integer, a list of integers, or a slice of integers.
import pandas as pd
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],
'Age': [24, 27, 22, 32, 29],
'City': ['New York', 'Los Angeles', 'Chicago', 'Houston', 'Phoenix'],
'Salary': [70000, 80000, 60000, 90000, 75000]
}
df = pd.DataFrame(data, index=['a', 'b', 'c', 'd', 'e'])
print("Original DataFrame:")
print(df)
# Select the row at integer position 2 (which is label 'c')
print("\nRow at integer position 2 using iloc:")
print(df.iloc[2])
# Select rows from integer position 0 up to (but not including) 3, and columns at positions 0 and 2
print("\nRows 0-2, columns 0 and 2 using iloc:")
print(df.iloc[0:3, [0, 2]])
# Select all rows, and the column at integer position 1 (Age)
print("\nAll rows, column at integer position 1 using iloc:")
print(df.iloc[:, 1])
Examples of using iloc for integer-location based indexing.
iloc, the end index is exclusive, just like standard Python list slicing. df.iloc[0:3] will select rows at positions 0, 1, and 2, but not 3.Key Differences and When to Use Each
The core distinction between loc and iloc lies in their approach to indexing: labels vs. integer positions. This difference dictates when and how you should use each. Understanding this is crucial for writing robust and readable Pandas code.
flowchart TD
Start[Start]
Start --> A{Need to select data?}
A -->|Yes| B{Do you know row/column LABELS?}
B -->|Yes| C[Use `df.loc[]`]
B -->|No| D{Do you know row/column INTEGER POSITIONS?}
D -->|Yes| E[Use `df.iloc[]`]
D -->|No| F[Consider resetting index or using boolean indexing with `loc`]
C --> End[End]
E --> End
F --> EndDecision flow for choosing between loc and iloc.
Here's a summary of their differences:
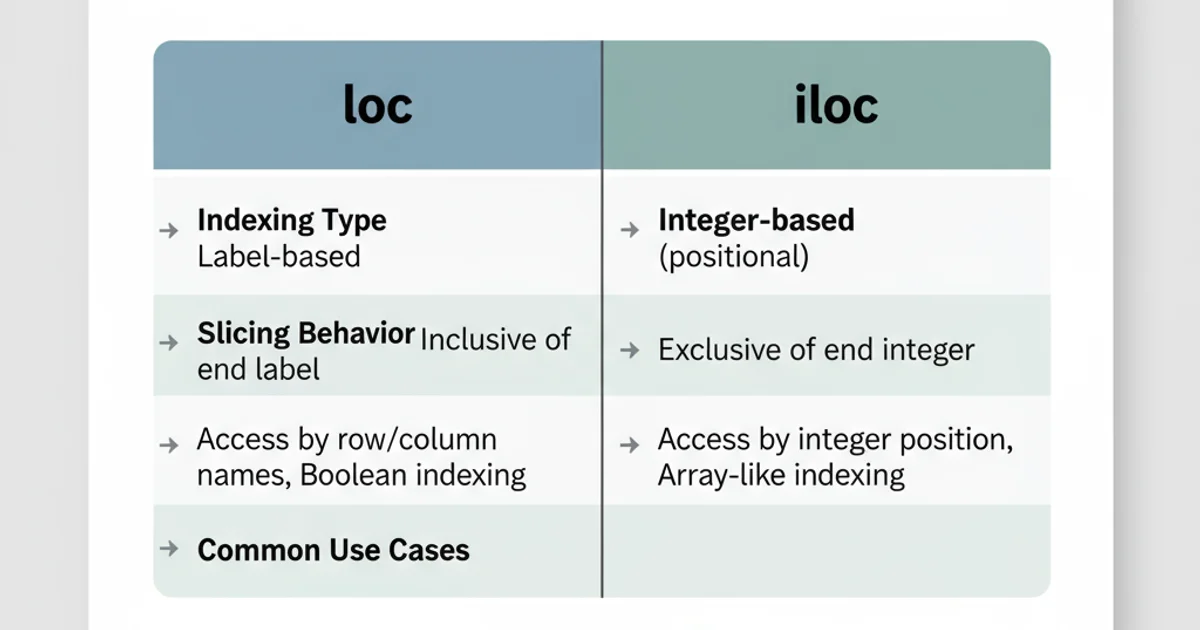
Comparison of loc and iloc features.
Choosing the right indexer depends on your specific needs:
Use
locwhen:- You want to select data based on explicit row and column names.
- Your DataFrame's index has meaningful labels (e.g., dates, IDs).
- You need to perform boolean indexing (e.g.,
df.loc[df['Age'] > 30]). - You want to modify data by label.
Use
ilocwhen:- You want to select data based on the integer position of rows and columns.
- You need to select the first N rows or last N rows, or specific rows by their order.
- You are iterating through rows or columns by their position.
- You are working with a DataFrame where the index labels are not unique or are less important than their positional order.
df.at[] and df.iat[] are optimized, faster versions of loc and iloc respectively. df.at['c', 'Name'] is faster than df.loc['c', 'Name'] for a single scalar lookup.