How branch predictor and branch target buffer co-exist?
Categories:
The Symbiotic Relationship: Branch Predictors and Branch Target Buffers
Explore how Branch Predictors and Branch Target Buffers work in tandem to optimize CPU pipeline performance by accurately predicting and quickly resolving branch instructions.
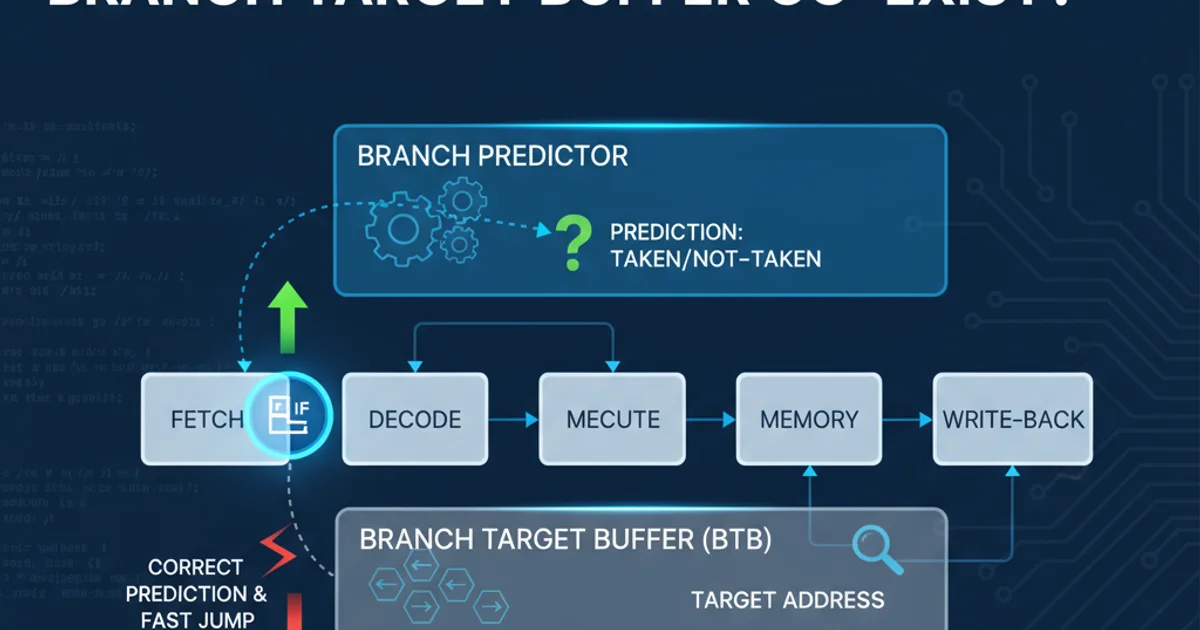
Modern CPUs rely heavily on pipelining to achieve high performance. However, branch instructions (like if statements, loops, and function calls) pose a significant challenge to pipelined execution. When a branch is encountered, the CPU doesn't immediately know which instruction to fetch next, leading to pipeline stalls. To mitigate this, CPUs employ sophisticated mechanisms: the Branch Predictor and the Branch Target Buffer (BTB). While often discussed together, they serve distinct yet complementary roles in ensuring a smooth instruction flow.
Understanding the Branch Predictor
The Branch Predictor's primary function is to guess whether a conditional branch will be taken or not taken. It doesn't care about the target address; its sole focus is on the direction of the branch. This prediction is crucial because fetching instructions from the wrong path can lead to a significant performance penalty when the misprediction is discovered, requiring the pipeline to be flushed and refilled.
Branch predictors use various algorithms, ranging from simple static predictors (e.g., always predict taken for backward branches) to complex dynamic predictors that learn from past behavior. Common dynamic predictors include:
- One-bit predictor: Stores the last outcome of a branch.
- Two-bit predictor: Uses a state machine to track recent outcomes, providing more resilience to occasional mispredictions.
- Global history predictors: Consider the outcomes of recent branches to predict the current one.
- Perceptron predictors: Use machine learning techniques to make predictions.
flowchart TD
A[Fetch Branch Instruction] --> B{Is it a conditional branch?}
B -->|Yes| C[Consult Branch Predictor]
C --> D{Prediction: Taken or Not Taken?}
D -->|Taken| E[Fetch from Predicted Target]
D -->|Not Taken| F[Fetch from Next Sequential Instruction]
B -->|No| G[Continue Sequential Fetch]
E --> H[Execute Instruction]
F --> H
G --> H
H --> I{Actual Outcome Known?}
I -->|Yes| J[Compare Prediction with Actual]
J -->|Misprediction| K[Flush Pipeline & Correct Path]
J -->|Correct Prediction| L[Update Predictor History (if dynamic)]Simplified Branch Prediction Flow
The Role of the Branch Target Buffer (BTB)
While the Branch Predictor determines if a branch is taken, the Branch Target Buffer (BTB) determines where a taken branch will go. The BTB is a cache that stores the target address of previously taken branch instructions. When a branch instruction is fetched, the CPU simultaneously checks the BTB. If the branch instruction's address is found in the BTB, it provides the predicted target address immediately, allowing the instruction fetch unit to start fetching instructions from the predicted target without waiting for the branch instruction to be decoded and its target address calculated.
The BTB typically stores pairs of (branch instruction address, target address). For indirect branches (e.g., jmp eax or call function_pointer), the BTB might also store multiple possible target addresses or use more advanced techniques like a Branch Target Address Cache (BTAC) or Return Address Stack (RAS) for function returns.
flowchart TD
A[Fetch Branch Instruction (Address X)] --> B{Is Address X in BTB?}
B -->|Yes| C[Get Predicted Target Address Y from BTB]
C --> D[Start Fetching from Address Y]
B -->|No| E[Decode Branch Instruction]
E --> F[Calculate Actual Target Address Z]
F --> G[Start Fetching from Address Z]
G --> H[Update BTB with (X, Z)]Branch Target Buffer (BTB) Lookup Process
Co-existence and Synergy
The Branch Predictor and BTB work in a tightly coupled manner. When a branch instruction is encountered:
- BTB Lookup: The instruction's address is sent to the BTB. If a hit occurs, the BTB provides a predicted target address.
- Branch Prediction: Simultaneously, the instruction's address is sent to the Branch Predictor, which predicts whether the branch will be taken or not taken.
If the Branch Predictor predicts 'taken' and the BTB provides a target address, the CPU can immediately start fetching instructions from that target address. This parallel operation is key to minimizing pipeline bubbles. If the predictor says 'not taken', the CPU continues fetching sequentially.
Upon execution of the branch, the actual outcome and target address are known. This information is then used to update both the Branch Predictor (for future direction predictions) and the BTB (for future target address lookups). A misprediction or BTB miss incurs a penalty, highlighting the importance of accurate and fast prediction mechanisms.
flowchart LR
subgraph CPU Pipeline
Fetch[Instruction Fetch]
Decode[Decode]
Execute[Execute]
Memory[Memory Access]
Writeback[Writeback]
end
Fetch --> BranchPredictor[Branch Predictor]
Fetch --> BTB[Branch Target Buffer]
BranchPredictor -- Predicts Direction (Taken/Not Taken) --> Fetch
BTB -- Provides Predicted Target Address --> Fetch
Fetch -- Branch Instruction --> Decode
Decode -- Actual Outcome & Target --> BranchPredictor
Decode -- Actual Outcome & Target --> BTB
BranchPredictor -- Updates Prediction History --> BranchPredictor
BTB -- Updates Target Address Cache --> BTB
style BranchPredictor fill:#f9f,stroke:#333,stroke-width:2px
style BTB fill:#bbf,stroke:#333,stroke-width:2pxInteraction between Branch Predictor and BTB in a CPU Pipeline
switch statements over complex if-else chains, or ensuring loops have predictable iteration counts) can significantly improve CPU performance by aiding both the Branch Predictor and BTB.In summary, the Branch Predictor and Branch Target Buffer are two indispensable components of modern high-performance processors. The Branch Predictor guesses the direction of a branch, while the BTB caches its target address. Together, they form a powerful prediction engine that allows the CPU to speculatively execute instructions, thereby masking the latency associated with control flow changes and keeping the pipeline full.