Size of a char in C
Categories:
Understanding the Size of a char in C

Explore the fundamental concept of the char data type in C, its size, and how it's influenced by system architecture and the C standard.
In the C programming language, the char data type is fundamental for storing character values. However, its exact size in bytes can sometimes be a source of confusion, especially for newcomers. This article delves into what defines the size of a char, how to determine it programmatically, and the implications for portability and character encoding.
The C Standard's Definition of char Size
The C standard (ISO/IEC 9899) defines char as the smallest addressable unit of memory. Crucially, it specifies that sizeof(char) is always 1. This doesn't mean a char is always 8 bits, but rather that the sizeof operator reports its size in units of char. The actual number of bits in a byte (and thus a char) is defined by the CHAR_BIT macro, found in the <limits.h> header. While CHAR_BIT is commonly 8 on most modern systems, it can theoretically be larger.
flowchart TD
A[C Standard Definition] --> B{"sizeof(char) == 1"}
B --> C[Smallest Addressable Unit]
C --> D{Number of Bits in a Byte?}
D --> E["Defined by CHAR_BIT (in <limits.h>)"]
E --> F["Commonly 8 bits (octet)"]
E --> G["Can be > 8 bits (rare)"]How the C Standard defines the size of char
Determining char Size Programmatically
To find the size of a char in bytes and bits on your specific system, you can use the sizeof operator and the CHAR_BIT macro. This is the most reliable way to understand the characteristics of char on the compilation target.
#include <stdio.h>
#include <limits.h>
int main() {
printf("Size of char (in bytes): %zu\n", sizeof(char));
printf("Number of bits in a byte (CHAR_BIT): %d\n", CHAR_BIT);
printf("Total bits for a char: %zu\n", sizeof(char) * CHAR_BIT);
return 0;
}
C code to determine the size of char in bytes and bits.
sizeof(char) and CHAR_BIT for portable code. Do not assume char is always 8 bits, even though it is the most common scenario.Implications for Character Encoding and Portability
The fact that char is guaranteed to be 1 byte (as reported by sizeof) but not necessarily 8 bits has implications for character encoding. For ASCII, which uses 7 bits, an 8-bit char is perfectly sufficient. However, for multi-byte encodings like UTF-8, a single logical character might require multiple chars for storage. When dealing with internationalization, it's crucial to understand that char represents a byte, not necessarily a full character in all encodings.
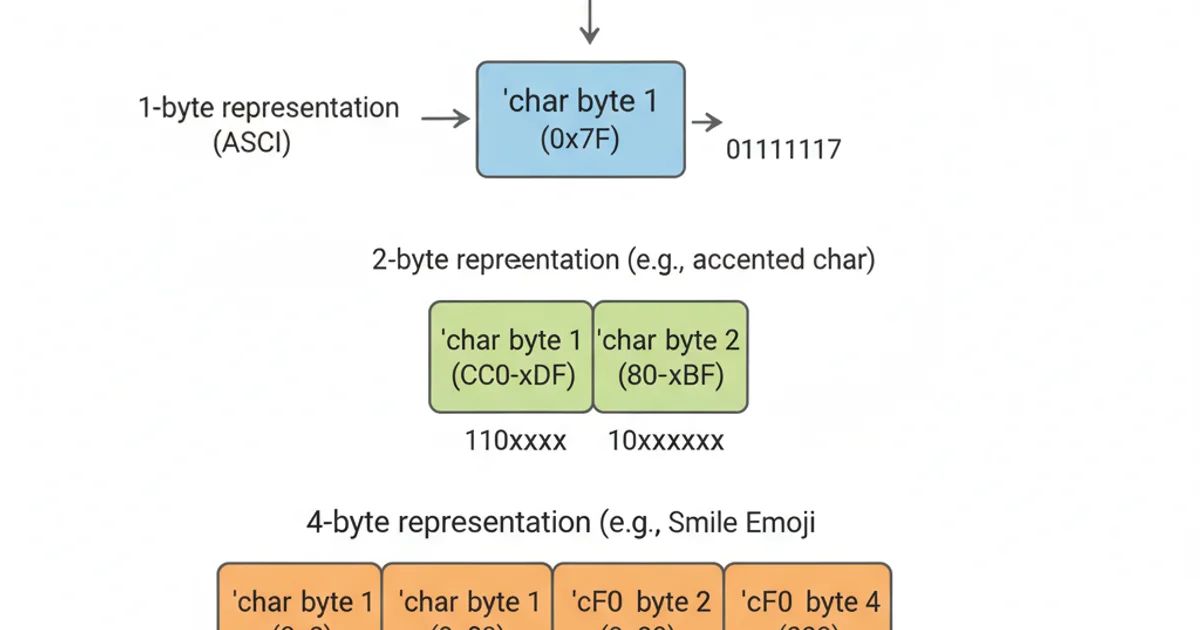
A single Unicode character can be composed of multiple char bytes in UTF-8.
wchar_t, char16_t, and char32_t types, defined in <wchar.h> and <uchar.h> respectively, which are better suited for representing characters beyond the basic execution character set.