Database sharding vs partitioning
Database Sharding vs. Partitioning: Scaling Strategies Explained

Explore the differences between database sharding and partitioning, two critical techniques for scaling large databases, and learn when to use each for optimal performance and manageability.
As applications grow, so does the data they manage. A single database server can quickly become a bottleneck, leading to performance degradation and scalability issues. To overcome these challenges, database architects employ various scaling strategies. Among the most common are sharding and partitioning. While both involve dividing a large database into smaller, more manageable pieces, they differ significantly in their approach, implementation, and the problems they solve. Understanding these distinctions is crucial for designing robust and scalable database systems.
What is Database Partitioning?
Database partitioning is a technique where a large table or index is divided into smaller, more manageable pieces called partitions, all residing within the same database instance. These partitions are typically based on a specific column's value (e.g., date, region, ID range). The primary goal of partitioning is to improve performance, manageability, and availability of very large tables. It's a form of horizontal scaling within a single database server.
graph TD
A[Large Database Table] --> B{Partition Key (e.g., Date, Region)}
B --> C[Partition 1 (e.g., Jan-Mar)]
B --> D[Partition 2 (e.g., Apr-Jun)]
B --> E[Partition 3 (e.g., Jul-Sep)]
B --> F[Partition 4 (e.g., Oct-Dec)]
C -- Resides on --> G[Single Database Server]
D -- Resides on --> G
E -- Resides on --> G
F -- Resides on --> GConceptual diagram of database partitioning within a single database server.
Common partitioning strategies include:
- Range Partitioning: Data is distributed based on a range of values in a column (e.g.,
ORDER_DATEbetween '2023-01-01' and '2023-03-31'). - List Partitioning: Data is distributed based on a predefined list of values in a column (e.g.,
REGIONin ('North', 'South')). - Hash Partitioning: Data is distributed based on a hash function applied to a column's value, ensuring an even distribution across partitions.
- Composite Partitioning: A combination of two partitioning methods, such as range-hash or list-range.
What is Database Sharding?
Database sharding, also known as horizontal partitioning, is a technique where a large database is divided into smaller, independent databases called shards. Unlike partitioning, these shards are typically hosted on separate database servers. Each shard contains a subset of the data and is fully functional as an independent database. The primary goal of sharding is to distribute the data and the load across multiple servers, enabling true horizontal scalability and overcoming the limitations of a single server.
graph TD
A[Large Database] --> B{Sharding Key (e.g., User ID, Geo-location)}
B --> C[Shard 1 (Server 1)]
B --> D[Shard 2 (Server 2)]
B --> E[Shard 3 (Server 3)]
C -- Contains subset of --> F[Application Data]
D -- Contains subset of --> F
E -- Contains subset of --> F
subgraph Distributed System
C
D
E
endConceptual diagram of database sharding across multiple independent servers.
Sharding strategies are similar to partitioning but applied at a higher level:
- Range-based Sharding: Data is distributed based on a range of values in the sharding key (e.g.,
USER_ID1-10000 on Shard 1, 10001-20000 on Shard 2). - List-based Sharding: Data is distributed based on specific values of the sharding key (e.g.,
COUNTRY= 'USA' on Shard 1,COUNTRY= 'Canada' on Shard 2). - Hash-based Sharding: A hash function determines which shard a record belongs to, aiming for even distribution.
- Directory-based Sharding: A lookup table (directory) maps sharding keys to specific shards, offering flexibility but introducing a single point of failure if not managed carefully.
Key Differences and Use Cases
The fundamental difference lies in their scope: partitioning divides a table within a single database, while sharding divides the entire database across multiple servers. This distinction leads to different benefits and challenges.
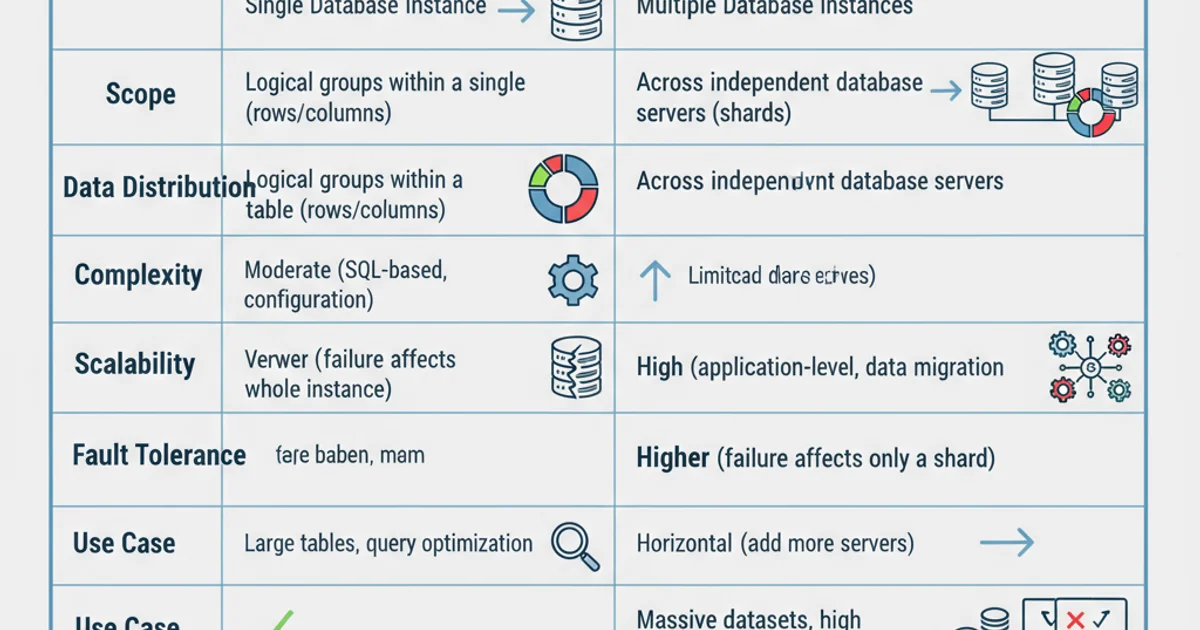
Comparison of Database Partitioning vs. Sharding
When to use Partitioning:
- You have a single very large table that is causing performance issues due to its size.
- You need to improve query performance by reducing the amount of data scanned.
- You want to manage data lifecycle (e.g., archiving old data) more efficiently.
- You need to perform maintenance operations on subsets of data without affecting the entire table.
- Your primary bottleneck is I/O on a single server, but CPU and memory are still sufficient.
When to use Sharding:
- Your entire database (not just a single table) is too large to fit on a single server.
- You've exhausted vertical scaling options (upgrading hardware).
- You need to distribute read/write load across multiple servers to handle high traffic.
- You require higher availability and fault tolerance, as the failure of one shard doesn't bring down the entire system.
- Your application demands extreme scalability that a single database instance cannot provide.
Implementing Partitioning in MySQL
MySQL supports various partitioning types. Here's a simple example of range partitioning a table by year.
CREATE TABLE sales (
id INT NOT NULL AUTO_INCREMENT,
amount DECIMAL(10, 2) NOT NULL,
sale_date DATE NOT NULL,
PRIMARY KEY (id, sale_date)
)
PARTITION BY RANGE (YEAR(sale_date)) (
PARTITION p2020 VALUES LESS THAN (2021),
PARTITION p2021 VALUES LESS THAN (2022),
PARTITION p2022 VALUES LESS THAN (2023),
PARTITION p2023 VALUES LESS THAN (2024),
PARTITION pmax VALUES LESS THAN MAXVALUE
);
Example of range partitioning a MySQL table by year.
Considerations for Sharding
Implementing sharding is a complex architectural decision with several challenges:
- Sharding Key Selection: Choosing the right sharding key is paramount. A poor choice can lead to hot spots (uneven data distribution) or make certain queries inefficient (e.g., queries that need to join data across multiple shards).
- Data Rebalancing: As data grows or access patterns change, shards may become unbalanced. Rebalancing data across shards is a non-trivial operation.
- Distributed Transactions: Maintaining ACID properties across multiple shards is challenging. Two-phase commit protocols are often used but add overhead.
- Cross-Shard Joins: Queries that require joining data from tables residing on different shards are complex and can be slow.
- Application Complexity: The application logic needs to be aware of the sharding scheme to route queries to the correct shard.
- Operational Overhead: Managing multiple database instances, backups, monitoring, and schema changes becomes significantly more complex.