Natural Language Parsing tools: what is out there and what is not?
Categories:
Natural Language Parsing Tools: What's Available and What's Missing?

Explore the landscape of Natural Language Parsing (NLP) tools, from established libraries to emerging technologies, and identify current gaps in functionality and research.
Natural Language Processing (NLP) is a rapidly evolving field that enables computers to understand, interpret, and generate human language. At its core, NLP relies heavily on parsing – the process of analyzing a sequence of tokens (words) to determine its grammatical structure. This article delves into the current state of NLP parsing tools, highlighting popular options, their capabilities, and areas where innovation is still needed.
The Foundation: Syntactic and Semantic Parsing
Natural Language Parsing broadly falls into two main categories: syntactic parsing and semantic parsing. Syntactic parsing focuses on the grammatical structure of sentences, identifying parts of speech, phrases, and dependencies between words. Semantic parsing, on the other hand, aims to understand the meaning or intent behind the language, often by mapping natural language to formal representations like logical forms or executable code.
flowchart TD
A[Natural Language Input] --> B{Parsing Process}
B --> C[Syntactic Parsing]
B --> D[Semantic Parsing]
C --> C1["Part-of-Speech Tagging"]
C --> C2["Dependency Parsing"]
C --> C3["Constituency Parsing"]
D --> D1["Named Entity Recognition"]
D --> D2["Relation Extraction"]
D --> D3["Abstract Meaning Representation"]
C1 & C2 & C3 --> E["Grammatical Structure"]
D1 & D2 & D3 --> F["Meaning Representation"]
E & F --> G[NLP Application Output]Overview of Syntactic vs. Semantic Parsing in NLP
Popular Syntactic Parsing Tools
Several robust libraries and frameworks offer excellent capabilities for syntactic parsing. These tools are often built on statistical models or deep learning architectures and provide functionalities like Part-of-Speech (POS) tagging, dependency parsing, and constituency parsing. They are fundamental for tasks ranging from information extraction to machine translation.
spaCy (Python)
import spacy
nlp = spacy.load("en_core_web_sm") doc = nlp("Apple is looking at buying U.K. startup for $1 billion.")
for token in doc: print(f"{token.text:<10} {token.pos_:<10} {token.dep_:<10} {token.head.text:<10}")
Output:
Apple PROPN nsubj looking
is AUX aux looking
looking VERB ROOT looking
at ADP prep looking
buying VERB pcomp at
U.K. PROPN compound startup
startup NOUN dobj buying
for ADP prep buying
$ SYM quantmod 1
1 NUM nummod billion
billion NUM pobj for
. PUNCT punct looking
NLTK (Python)
import nltk from nltk.tokenize import word_tokenize from nltk.tag import pos_tag from nltk.chunk import ne_chunk
text = "The quick brown fox jumps over the lazy dog." tokens = word_tokenize(text) pos_tags = pos_tag(tokens)
print("POS Tags:", pos_tags)
Example of a simple grammar for constituency parsing (requires a parser)
grammar = "NP: {?*}"
cp = nltk.RegexpParser(grammar)
tree = cp.parse(pos_tags)
tree.pretty_print()
Output:
POS Tags: [('The', 'DT'), ('quick', 'JJ'), ('brown', 'JJ'), ('fox', 'NN'), ('jumps', 'VBZ'), ('over', 'IN'), ('the', 'DT'), ('lazy', 'JJ'), ('dog', 'NN'), ('.', '.')]
Stanford CoreNLP (Java/Python)
Example using Stanford CoreNLP via Python wrapper (pycorenlp)
Requires Stanford CoreNLP server running
from pycorenlp import StanfordCoreNLP
nlp = StanfordCoreNLP('http://localhost:9000') text = 'Stanford University is a leading institution.'
output = nlp.annotate(text, properties={ 'annotators': 'pos, parse, depparse', 'outputFormat': 'json' })
print(output['sentences'][0]['parse']) print(output['sentences'][0]['basicDependencies'])
Output (truncated for brevity):
(ROOT (S (NP (NNP Stanford) (NNP University)) (VP (VBZ is) (NP (DT a) (VBG leading) (NN institution))) (. .)))
[{'dep': 'ROOT', 'governor': 0, 'governorGloss': 'ROOT', 'dependent': 3, 'dependentGloss': 'is'}, ...]
Challenges and Gaps in Current Parsing Tools
Despite significant advancements, several challenges persist in NLP parsing. Ambiguity remains a major hurdle, as human language is inherently ambiguous at both syntactic and semantic levels. Handling highly informal text, code-switching, and low-resource languages also presents difficulties. Furthermore, achieving truly deep semantic understanding that goes beyond surface-level meaning is an ongoing research area.
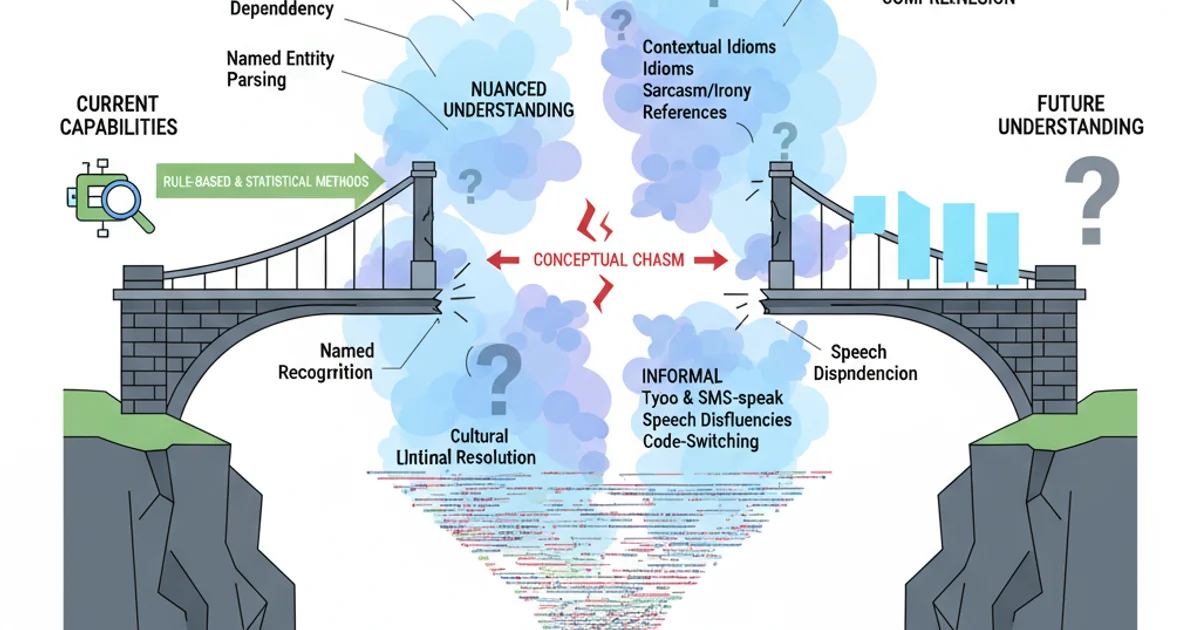
Conceptual gaps in current NLP parsing capabilities.
Emerging Trends and Future Directions
The field is continuously evolving, with new models and techniques addressing these gaps. Transformer-based models like BERT, GPT, and their successors have revolutionized NLP, offering improved contextual understanding and transfer learning capabilities. Research is also focusing on multimodal parsing (combining text with images or audio), cross-lingual parsing, and developing more robust methods for handling domain-specific jargon and highly specialized language.
graph TD
A[Current NLP Parsing] --> B{Challenges}
B --> B1["Syntactic Ambiguity"]
B --> B2["Semantic Ambiguity"]
B --> B3["Informal Text / Slang"]
B --> B4["Low-Resource Languages"]
B --> B5["Deep Semantic Understanding"]
A --> C{Emerging Solutions}
C --> C1["Transformer Models (BERT, GPT)"]
C --> C2["Multimodal Parsing"]
C --> C3["Cross-Lingual Transfer Learning"]
C --> C4["Domain-Specific Adaptation"]
C1 --> D["Improved Contextual Understanding"]
C2 --> E["Integrated Text & Visual/Audio Analysis"]
C3 --> F["Better Support for Diverse Languages"]
C4 --> G["Enhanced Performance in Niche Domains"]
D & E & F & G --> H[Future of NLP Parsing]Challenges and Emerging Solutions in NLP Parsing
The journey towards truly human-like language understanding is long, but the progress in NLP parsing tools is undeniable. From foundational libraries providing robust syntactic analysis to cutting-edge deep learning models pushing the boundaries of semantic comprehension, the toolkit available to developers and researchers is richer than ever. The ongoing research into addressing ambiguity, handling diverse language forms, and achieving deeper meaning extraction promises an even more sophisticated future for NLP.